
Data Science Weekly - Issue 651
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #651
May 14, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let’s dive into some interesting links from this week.
Editor's Picks
Marco Polo: Finding a friend with only distance and motion.
You walk into a cafe, looking for your friend. Seems like an easy task, until you see it’s so packed that you can’t see through the crowd at all, and everyone’s talking so loud that you can barely hear anything. The only things you know are your movements, and how far you are from your friend (through the special psychic bond you two share). How will you find each other?...I wanted to solve the exact same problem, but with devices instead of people (so no psychic connection for me), existing in a space of hundreds of other devices. Working the problem taught me a lot of really interesting science relating to robotics and state estimation, and I wrote this post so you can learn, too…
Biology is a Burrito
A bacterium’s genome, pulled into a straight thread, is nearly 1,000 times longer than the cell from which it came. If you placed one E. coli into a gallon-sized jug with some nutrients and waited a few hours, the genomes of its descendants, placed end-to-end, would reach to the moon and back...several times….The truth is that biochemistry textbooks often depict cells as spacious places, where molecules float in secluded harmony. “But a cell looks more like a burrito,” says Michael Elowitz, a biologist at Caltech. All the biochemicals are pushed together, bumping into each other…Softmax, can you really derive the Jacobian? And should you care?
Multiclass output? Softmax. Normalising probabilities? Softmax. Attention weights? Softmax. Partition function? You guessed it, Softmax. This function comes up everywhere, but how often have you really thought about what’s going on inside?…What does softmax actually do to your distribution?…The softmax function is deceptively simple…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
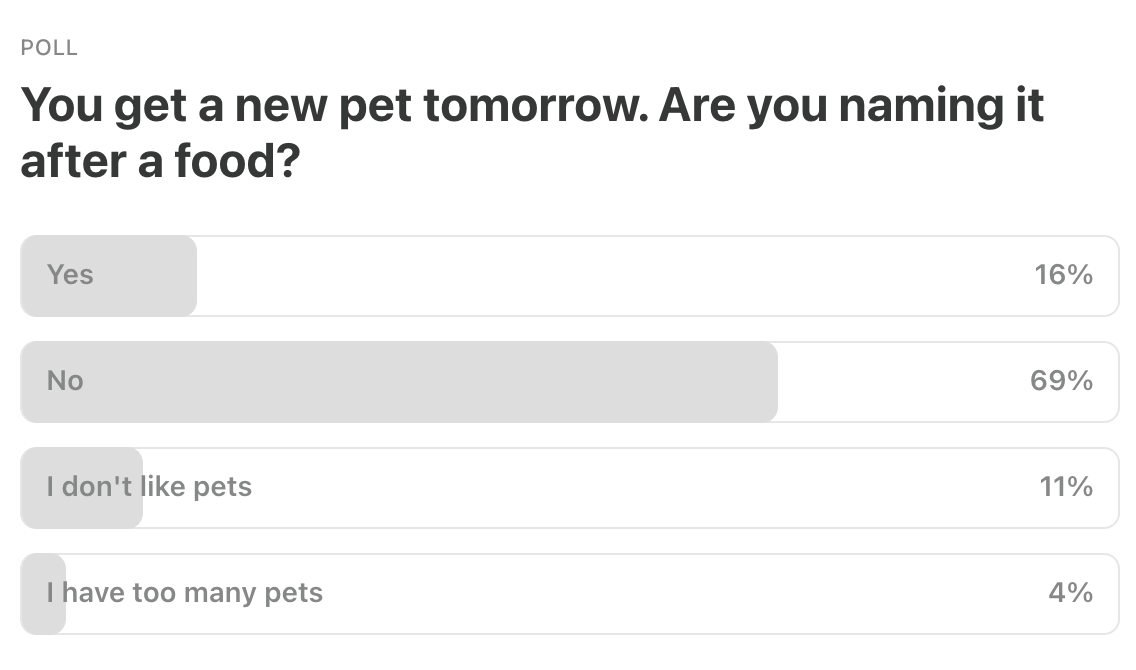
.
Data Science Articles & Videos
Illusions of Understanding in the Sciences
The first part of this essay supports the case for the universality of partial and incomplete levels of understanding by showing the difficulty of reaching a deep level of understanding for even a simple analysis and model that most scientists use and believe they understand: linear regression. The second part highlights some implications of the existence of many levels of understanding and explanation, and their use by scientists for design, testing, analysis, and theory development. It discusses the way that deduction and induction depend on the levels of understanding and the implications of the illusion that a scientist’s understanding is deep…People Interested in Continual Learning Research [Reddit]
Recently, I’ve become fascinated by Continual Learning, especially the idea of AI systems that can continuously adapt and improve from experience rather than staying static after training. I’m a student just starting my journey in CL research and would love to connect with people exploring similar ideas. Whether you’re a student, researcher, or just curious about the field, feel free to DM me. Would also love paper recommendations and interesting research directions…
You Should Probably Map That: Introduction to Geospatial Analysis in R
Anjile An, Weill Cornell Medical College…Data comes in many forms, but the spatial components can be overlooked. You’ll get some history of mapping and learn the basic building blocks of spatial data. The demo portion will go over how to use the trusty {ggplot2} as well as some new tools like {sf} and {tmap} to plot different types of spatial data…Requirements analysis: catching requirement bugs before they become code
Every experienced engineer has a story where a feature shipped, worked on the happy path, and then quietly did the wrong thing on some edge case no one had thought about. Trace the bug back far enough and it rarely ends at the code; it ends at a sentence in a requirement document that meant one thing to the person who wrote it and something else to the person who implemented it…Teaching <Fundamentals of Machine Learning>
This past spring, i taught <Fundamentals of Machine Learning> for computer science seniors (with some juniors as well as seniors from other majors, including data science and economics) at NYU. last time i taught this course, the course was titled <Introduction to Machine Learning>, it was pre-ChatGPT and it was pre-pandemic; in fact, i was teaching this course in the spring of 2020, and the whole university, city and world went into its first lock down mid-way. in other words, i taught this course in the old world, and i was asked to teach this course in this brave new world…
Interactive Jensen–Shannon Divergence Visualisation
An interactive visualisation of Jensen–Shannon divergence - the symmetric, always-finite cousin of KL. Shape two distributions and watch JSD, its ceiling of one bit, and the per-point contribution respond in real time…70 years of love, empowerment, and freedom. Here’s a look at Eurovision by its lyrics.
Famous for its upbeat rhythms, flamboyant performances, and political voting patterns, the competition has another dimension that moves with the zeitgeist: its song lyrics…What I’m Hearing About Cognitive Debt (So Far)
A week ago, I wrote about how Generative and Agentic AI may be amplifying what I’ve been calling cognitive debt: the accumulated gap between a system’s evolving structure and a team’s shared understanding of how and why that system works and can be changed over time. The post sparked thoughtful discussion across different communities. Rather than respond thread by thread, I want to synthesize what I’m hearing and connect it to other reflections I’ve been reading. I will likely update this as the conversation evolves…The most direct way to compress an embedding (other than quantization) is to fit PCA on the corpus and keep the top-d eigenvectors. It works, but PCA is a linear projection, and neural-network embeddings on the sphere are structurally nonlinear — the well-known cone effect in transformers. Some of the variance lives in a nonlinear tail that a linear decoder can’t reach…This post is about a closed-form way to add a quadratic decoder on top of PCA, to capture part of that nonlinear tail. The encoder stays as plain PCA. The decoder is a degree-2 polynomial lift plus Ridge OLS (ordinary linear regression with L2 regularization), also closed-form. No SGD, no epochs, no hyperparameter search. One np.linalg.solve over corpus statistics…
Visualize the Brrr - Learn GPU programming
Who This Is For: This is for anyone interested in GPU programming or performance engineering, whether you’re writing CUDA, HIP, Triton, cuTile, Gluon, Helion, JAX, or nothing at all. If you’ve ever struggled to conceptualize parallelism, memory coalescing, or tiling, these visualizations are meant to make those ideas concrete. No prior GPU experience required.What You’ll Learn: The lessons walk through fundamental concepts of GPU programming, parallelism, memory hierarchy, and more. Each chapter pairs a short explanation with an interactive visualization you can poke at…
PyTrendy is a robust solution for identifying and analyzing trends in time series. Unlike other trend detection packages, it is robust to noisy & flat segments, and handles for gradual & abrupt trend cases with a high precision. It aims to be the best package for trend detection in python…
Standardization vs Log transform? [Reddit]
I have been trying to understand the use cases of both of these and I am really confused. I know log transform fixes the features and makes their distribution normal and standardization on the other hand only fixes the scale of the feature by keeping the distribution the same. Are these things which I use one after the other ? Or just simply use one depending on the case (which I also don’t understand when) ?…AI agents can create convincing ecological models, but you still need to know what you’re doing
Agentic AI tools like Claude Code can write and run code, fix its own errors, and produce a formatted report with figures. I wanted to know whether that translates into reliable ecological modelling, so we ran a test: three fisheries tasks, four AI models, ten independent runs each, scored against a rubric. The results are published in Fish and Fisheries. We found agents can be genuinely useful, but only if you know how to use them well and only if you know enough about the analysis to catch what they miss…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #650 here.
Cutting Room Floor
Notes on Category Theory with examples from basic mathematics
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
Assessing Credit Score Prediction Reliability Using Bootstrap Resampling
Publishing a Quarto Blog: What I Learned Moving from Netlify to GitHub Pages
.
Whenever you're ready, 3 ways we can help:
Go deeper each week (paid subscription)
Get 3 additional posts per week designed to help you:Statistics → understand the math behind ML
AI Agents → build with modern AI tools
Career → become more valuable at your job
Looking to get a job?
A practical guide to landing your first (or next) data science role, based on thousands of reader questions.
👉 Check out our “Get A Data Science Job” CoursePromote your organization/project/event to ~68,500 subscribers
Sponsor this newsletter and reach a highly engaged data science audience (30–35% open rate).
👉 Reply to this email to learn more
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian