
Data Science Weekly - Issue 585
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #585
February 07, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
AI Engineering with Chip Huyen
Chip Huyen is the author of the freshly published O’Reilly book AI Engineering an expert in applied machine learning. What is AI engineering, and what are good ways in getting started with it?…
Thou Shalt Not Overfit
Time to bite the bullet and go in on this one again. I’ve written about overfitting extensively, both on this blog and in papers. A central line of my research for the last ten years has been motivated by the observation that overfitting doesn’t exist. We need to abandon the term. Let me try to motivate a different view through the lens of evaluation…Understanding Reasoning LLMs
This article describes the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this provides valuable insights and helps you navigate the rapidly evolving literature and hype surrounding this topic…
What’s on your mind
This Week’s Poll:
AI-Enbaled coding?
[Take this quick 5-second poll →]
We’ll share the results next week!
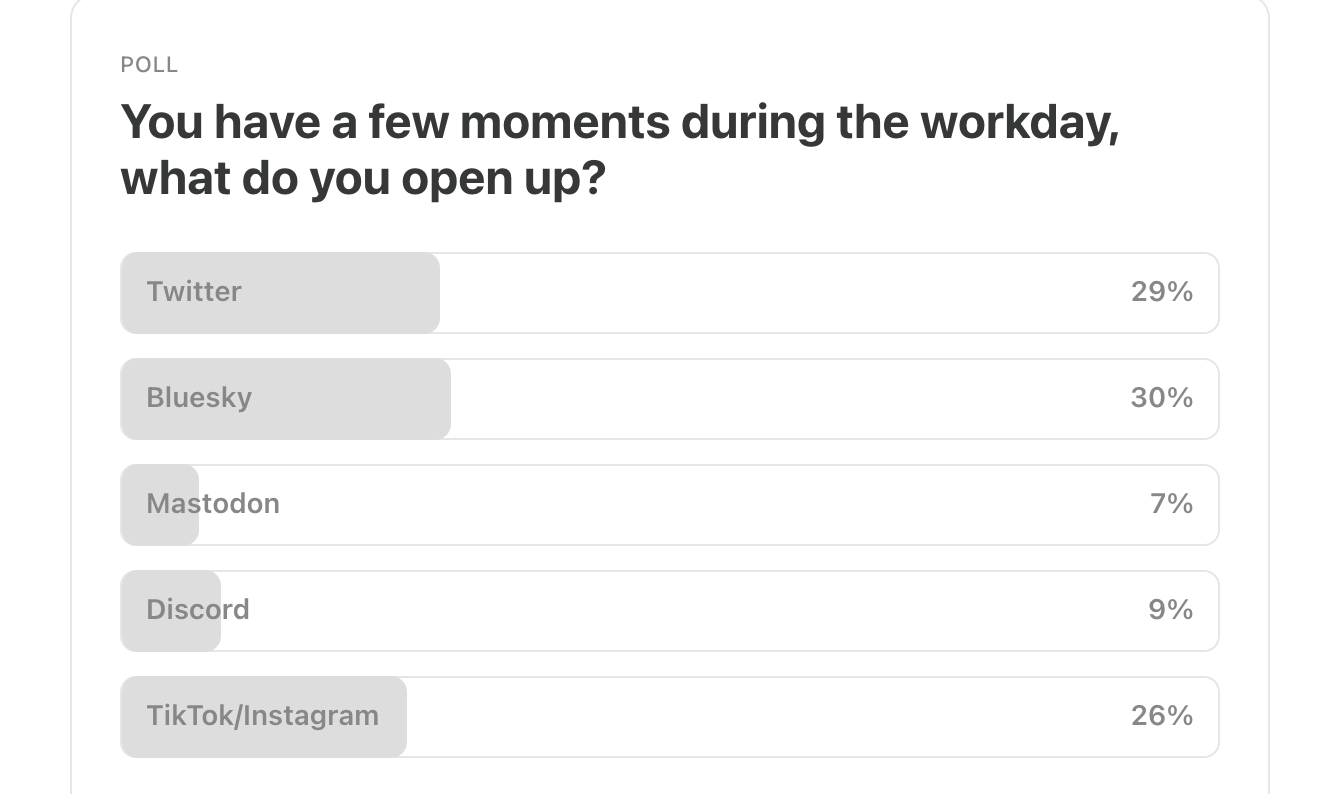
Last Week’s Poll:
Data Science Articles & Videos
Why Pivot Tables Never Die
In 2025, we're witnessing something remarkable - modern data tools are bringing pivot tables back to the forefront. But why would cutting-edge platforms invest in a decades-old spreadsheet feature? The answer lies in what made pivot tables revolutionary in the first place: turning complex data into instant insights without writing a single line of code…Some Lessons on Reviews and Rebuttals
Writing and responding to reviews is the bread and butter of any academic and especially in AI research, PhD students are confronted with both rather early compared to other displicines. Unfortunately, I found that drafting reviews and rebuttals is a skill that is rarely properly taught as part of PhD programs. Thus, in this article, I want to share some of the lessons I learned throughout the past 7 years…One Semester Is All You Need
These roadmaps are mainly targetted towards beginners who are right now in college, to get them started quickly. This is NOT for people who want to go deep on these topics…You are given a specific list of tasks to complete and resources to study from for each month. We have picked them in such a way that you should not need any more resources to unnecessarily be stuck in tutorial hell…Generative AI as a tool to accelerate the field of ecology
Here we draw upon a range of fields to discuss unique potential applications in which generative AI could accelerate the field of ecology, including augmenting data-scarce datasets, extending observations of ecological patterns and increasing the accessibility of ecological data…Matching, missing data, a quasi-experiment, and causal inference--Oh my!
I have a project for work where the goal is to compare two non-randomized groups. One group received an experimental intervention, and we’d like to compare those folks to their peers who were not offered that same intervention. We have easy access to data from folks from the broader population during the same time period, so the goal isn’t so bad as far as quasi-experiments go…The team would like to improve the comparisons by using matching, and we have some missing data issues in the matching covariate set. I haven’t done an analysis quite like this before, so this post is a walk-through of the basic statistical procedure as I see it…Steady on! Separating Failure-Free Ordering from Fault-Tolerant Consensus
This post continues my series looking at log replication protocols, within the context of state-machine replication (SMR) or just when the log itself is the product (such as Kafka). I’m going to cover some of the same ground from the Introduction to Virtual Consensus in Delos post, but focus on one aspect specifically and see how it generalizes…group relative policy optimization (GRPO)
I will explain and implement GRPO in an intuitive way - prerequisites: - you should be familiar with neural networks and gradient descent - you should be familiar with pytorch - it's okay if you are not familiar with deep RL..Look at Your Data: Debugging, Evaluating, and Iterating on Generative AI Systems
In this live-streamed fireside chat, Hugo Bowne-Anderson and Hamel Husain will explore how to:Use error analysis to identify the biggest pain points in your LLM workflows.
Build evaluation frameworks that connect directly to your product goals.
Develop a curiosity-driven approach to looking at data and traces, so you can iterate faster.
Understand why debugging is the cornerstone of building reliable, scalable generative AI systems…
A vision researcher’s guide to some RL stuff: PPO & GRPO
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks, and there’s also a quick summary of the tricks I find impressive in the DeepSeek R1 tech report in the end. This is all done by someone who’s mostly worked on vision and doesn’t know much about RL. If that’s you too, I hope you will find this helpful…
For a take-home performance project that's meant to take 2 hours, would you actually stay under 2 hours? [Reddit Discussion]
I've finished and I spent way more than 2 hours on this, as I feel like in this job market, I shouldn't take the risk of turning in a sloppier take home task. I've looked around and seen that others who were given 2 hour take homes also spent way more time on their tasks as well. It just feels like common sense to use all the time I was actually given, especially since other candidates are going to do so as well, but I'm worried that a hiring manager and recruiter might look at this and think "They obviously spent more than 2 hours"…Six Effective Ways to Reduce Compute Costs
In today’s article, I will cover the common ways to reduce the compute costs. Since I have worked on AWS for the most part, I will talk from the EC2 perspective, however it can be applied to other cloud platforms. These techniques may look very common sense but overlooked mostly leading to an expensive bill. Let’s revisit and refresh our memory…Designing monochrome data visualisations
In data visualisations, colours are often used to show values or categories of data. However, sometimes you might not be able to or want to use colour. This blog post discusses some tips for designing better visualisations when you're restricted to a monochrome palette…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #584 here.
Cutting Room Floor
Thank you
for reading
this far :)
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~66,500 subscribers by sponsoring this newsletter. 35-45% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Given the continuing interest in R1 (and DeepSeek in general), the following report provides insights into s1 and DeepSeek-R1 that you may find valuable:
From Brute Force to Brain Power: How Stanford's s1 Surpasses DeepSeek-R1
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5130864