
Data Science Weekly - Issue 587
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #587
February 20, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Emerging Patterns in Building GenAI Products
As we move software products using generative AI technology from proof-of-concepts into production systems, we are uncovering a range of common patterns. Evals play a central role in ensuring that these non-deterministic systems are operating within sensible boundaries. Large Language Models need enhancement to provide information beyond a generic and static training set. Most of the time we can do this with Retrieval Augmented Generation (RAG), although the basic RAG approach requires several patterns to overcome its limitations. When RAG isn't enough, Fine Tuning becomes worthwhile…
TrueSkill Part 1: The Algorithm
Who is the greatest boxer of all time? Who is the ‘GOAT?’ Is it Muhammad Ali? Mike Tyson? Someone else?…Introduced in Herbrich et al. (2007), the TrueSkill algorithm captures these effects beautifully. With some extensions, Microsoft deploys it at scale to matchmake many millions of gamers annually. Beyond its applied utility, it is an exceptional victory for Bayesian methods, where simple assumptions and probabilistic reasoning produce accurate estimates of counterfactual matchups…Further, the algorithm is game agnostic. All that is needed is when-and-who data on matches. As such, it can be applied to boxing, tennis, chess, MMA, and others. In fact, it can be applied to arbitrarily team multiplayer games, like Halo…Help the New Guy Survive SQL Hell [Reddit]
First real job in the data world…Pretty old warehouse that runs entirely on SQL Server. They put a new team on this project. Only one guy from the old crew has any idea what's happening (and even he's mostly reverse-engineering and guessing his way through). There's no proper documentation…I'm tasked with understanding the existing warehouse and building documentation, along with helping in maintenance tasks. Now, this warehouse looks like quite the maze to me…
What’s on your mind
This Week’s Poll:
Work from home?
[Take this quick 5-second poll →]
We’ll share the results next week!
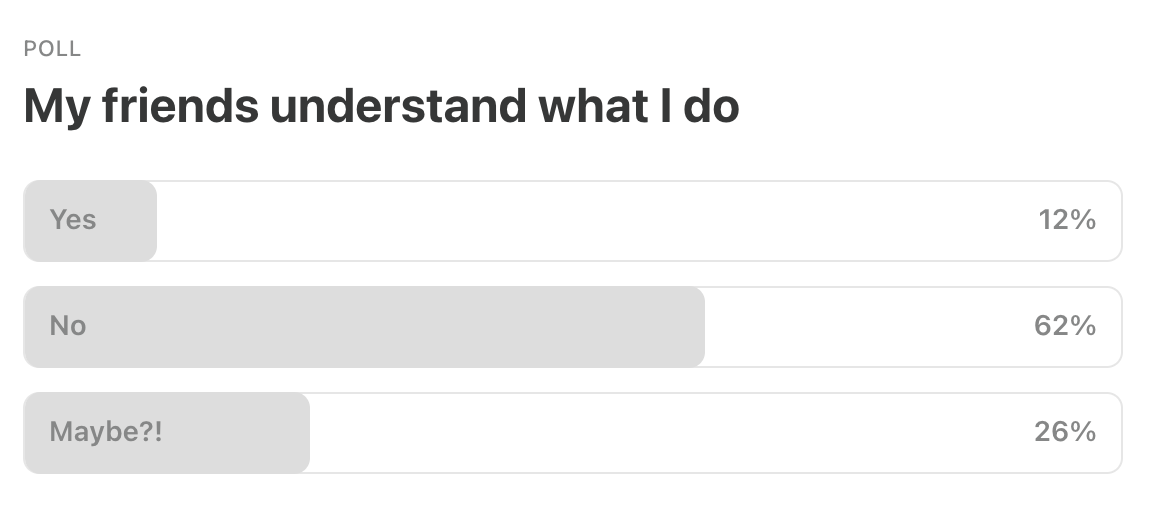
Last Week’s Poll:
Data Science Articles & Videos
Towards composable data platforms
I’ve written extensively about the open table formats (OTFs - Apache Iceberg, Delta Lake, and Apache Hudi). In my original Tableflow post, I wrote that shared tables were one of the major trends, enabled by the OTFs…But we can also view OTFs as enabling a kind of virtualization. In this post, I will start by explaining my take on OTFs and virtualization…DuckDB Newsletter: Learn DuckDB by example
Get your dose of DuckDB tips, SQL tricks, and links to learn more about the swiss knife of analytical databases…What is your daily/weekly routine if you have a WFH position? [Reddit]
I'm asking this here since data science/analytics is a very remote industry. I'm honestly trying to figure out a good cadence of when to make breakfast and get coffee, when to meal prep, when to get a 15 minute walk in, when to work out, do my hobbies etc., without driving myself insane…What is your routine for keeping up with life while you're working remotely?…Incremental Archival from Postgres to Parquet for Analytics
Ideally, data would get automatically archived in cheap storage, in a format optimized for large analytical queries.We developed two open source Postgres extensions that help you do that:
pg_parquet can export (and import) query results to the Parquet file format in object storage using regular COPY commands
pg_incremental can run a command for a never-ending series of time intervals or files, built on top of pg_cron
With some simple commands, you can set up a reliable, fully automated pipeline to export time ranges to the columnar Parquet format in S3…
Step-by-Step Diffusion: An Elementary Tutorial
We present an accessible first course on diffusion models and flow matching for machine learning, aimed at a technical audience with no diffusion experience. We try to simplify the mathematical details as much as possible (sometimes heuristically), while retaining enough precision to derive correct algorithms…Semantic Layers: The Missing Link Between AI and Data with David Jayatillake from Cube
In this episode, we chat with David Jayatillake, VP of AI at Cube, about semantic layers and their crucial role in making AI work reliably with data. We explore how semantic layers act as a bridge between raw data and business meaning, and why they're more practical than pure knowledge graphs. David shares insights from his experience at Delphi Labs, where they achieved 100% accuracy in natural language data queries by combining semantic layers with AI, compared to just 16% accuracy with direct text-to-SQL approaches…Bottom up Architecture
Although architects get a bad rap, I do think architecture is an important aspect of software engineering and the better question is to figure out how to get to an architecture that enables different teams to operate more independently…In this post, I’m discussing what software architecture even is and offer some thoughts on a bottom up approach…Data Science is losing its soul [Reddit]
DS teams are starting to lose the essence that made them truly groundbreaking. their mixed scientific and business core. What we’re seeing now is a shift from deep statistical analysis and business oriented modeling to quick and dirty engineering solutions. Sure, this approach might give us a few immediate wins but it leads to low ROI projects and pulls the field further away from its true potential. One size-fits-all programming just doesn’t work. it’s not the whole game…We often start coding to avoid "by hand" work. Here's why labeling your own data is worth the time…
How to use a histogram as a legend in {ggplot2}
Land isn’t unemployed—people are. Here’s how to use R, {ggplot2}, {sf}, and {patchwork} to create a histogram legend in a choropleth map to better see the distribution of values…When calibration beats metrics
Having a classifier with great metrics is good, but it is not enough for it to be useful in production. One reason why it might still fail is because it could be that you are dealing with a badly calibrated model. The predictions might be fine, but the probability estimates can be way off…In this video we talk about how to think about calibration and what it means…If spreadsheets are eternal, are BI tools transitory?
Consider the following scenario in the Microsoft stack: ingest data with ADF, transform with Fabric (& maybe dbt?), build a semantic model in Power BI, and delicately craft an artisanal dashboard (with your mouse). Then your stakeholder takes a look at your dashboard, navigates to the top left corner and clicks “Analyze In Excel”. How did we get here?…Building a SNAP LLM eval: part 1
This is the first write-up in a series about our process of building an "eval" — evaluation — to assess how well AI models perform on prompts related to the USA’s SNAP (food stamp) program…By sharing how we are approaching this for SNAP in some detail — including publishing a SNAP eval — we hope it will make it easier for others to do the same in similar problem spaces that matter for lower income Americans: healthcare (e.g. Medicaid), disability benefits, housing, legal help, etc…While evaluation can be a fairly technical topic, we hope these posts reduce barriers to more domain-specific evaluations being created by experts in these high-impact — but complex — areas…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #586 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~66,600 subscribers by sponsoring this newsletter. 35-45% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
https://sciencesaves.org/about-national-science-appreciation-day/?emci=28a86fad-baef-ef11-90cb-0022482a94f4&emdi=f486c054-c5ef-ef11-90cb-0022482a94f4&ceid=574939