
Data Science Weekly - Issue 592
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #592
March 27, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
New Book Release Teaches Essential API Skills for Data Scientists
API development has become a critical skill for data scientists, and a new book from O’Reilly Publishing provides practical experience with the latest Python frameworks. Hands-on APIs for AI and Data Science, an Amazon #1 New Release from O'Reilly Publishing is one of the first books to focus on the skills data scientists and machine learning engineers need to use APIs in their work…
Which Countries Have the Most Unique Taste in Music? A Statistical Analysis
Today we'll delve into global music tastes, highlighting nations with vibrant local cultures and thriving music industries, as well as those more closely aligned with Global Top 50…Common statistical tests are linear models (or: how to teach stats)
This document is summarised in the table below. It shows the linear models underlying common parametric and “non-parametric” tests. Formulating all the tests in the same language highlights the many similarities between them…
What’s on your mind
This Week’s Poll:
Take this quick 5-second poll →
We’ll share the results next week!
Last Week’s Poll:
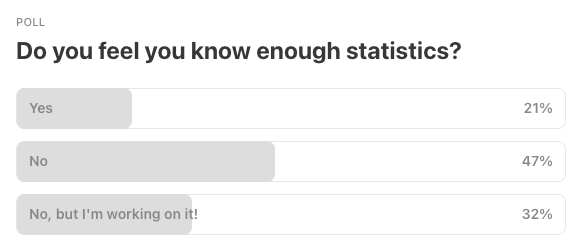
Data Science Articles & Videos
Improving Recommendation Systems & Search in the Age of LLMs
Here, we’ll discuss how industrial search and recommendation systems have evolved over the past year or so and cover model architectures, data generation, training paradigms, and unified frameworks:Data Science Agent in Colab: The future of data analysis with Gemini
Data Science Agent in Colab creates notebooks for trusted testers using Gemini, removing tedious setup tasks like importing libraries, loading data, and writing boilerplate code. Trusted testers are enthusiastic about the Data Science Agent, reporting they are able to streamline workflows and uncover insights faster than ever before…Reinforcement Learning: A Comprehensive Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based method, policy-gradient methods, model-based methods, and various other topics (e.g., multi-agent RL, RL+LLMs, and RL+inference)…One or Two? How Many Queues?
There’s a well-known rule of thumb that one queue is better than two. When you’ve got people waiting to check out at the supermarket, having a single shared queue improves utilization and reduces wait times. The reason for this is pretty simple: it avoids the case where somebody is waiting in a queue while there’s a checker available to do the work. It also saves the sanity of the person standing behind a cheque writer or expired coupon negotiator. But one queue isn’t always better than two…New dataset just dropped: JFK Records [Reddit]
Ever worked on a real-world dataset that’s both messy and filled with some of the world’s biggest conspiracy theories?…I wrote scripts to automatically download and process the JFK assassination records. That’s ~2,200 PDFs and 63,000+ pages of declassified government documents. Messy scans, weird formatting, and cryptic notes? No problem. I parsed, cleaned, and converted everything into structured text files. But that’s not all. I also generated a summary for each page using Gemini-2.0-Flash, making it easier than ever to sift through the history, speculation, and hidden details buried in these records…Efficient Filter Pushdown in Parquet
How to implement efficient filter pushdown in Parquet readers and why it’s challenging in practice…In the previous post, we discussed how DataFusion prunes Parquet files to skip irrelevant files/row_groups (sometimes also pages). This post discusses how Parquet readers skip irrelevant rows while scanning data…The Cybernetic Teammate
This past summer we conducted a pre-registered, randomized controlled trial of 776 professionals at Procter and Gamble, the consumer goods giant, to find out…When working without AI, teams outperformed individuals by a significant amount, 0.24 standard deviations (providing a sigh of relief for every teacher and manager who has pushed the value of teamwork). But the surprise came when we looked at AI-enabled participants. Individuals working with AI performed just as well as teams without AI, showing a 0.37 standard deviation improvement over the baseline. This suggests that AI effectively replicated the performance benefits of having a human teammate – one person with AI could match what previously required two-person collaboration…LLMOps Is About People Too: The Human Element in AI Engineering
When teams deploy generative AI, it's easy to focus solely on models, pipelines, and frameworks—and overlook the human factors critical to success. Misaligned executive expectations, resistance from subject-matter experts, and ineffective team structures often pose greater challenges than the technology itself. In this article, you'll learn practical strategies for aligning executives, engaging experts early, and structuring teams effectively: essential solutions for overcoming human-centric LLMOps hurdles and ensuring successful AI deployments…There are many ways to improve a classifier, but the most inspiring way to improve it is to really think hard on how you want to apply your model. The reason is because there might just be an amazing opportunity to use variable thresholds, which can really make the model more flexible in production…
Reducing Cloud Spend: Migrating Logs from CloudWatch to Iceberg with Postgres
As a database service provider, we store a number of logs internally to audit and oversee what is happening within our systems. When we started out, the volume of these logs is predictably low, but with scale they grew rapidly. Given the number of databases we run for users on Crunchy Bridge, the volume of these logs has grown to a sizable amount. Until last week, we retained those logs in AWS CloudWatch. Spoiler alert: this is expensive…
Dremel: A Decade of Interactive SQL Analysis at Web Scale [PDF]
Google’s Dremel was one of the first systems that combined a set of architectural principles that have become a common practice in today’s cloud-native analytics tools, including disaggregated storage and compute, in situ analysis, and columnar storage for semistructured data…In this paper, we discuss how these ideas evolved in the past decade and became the foundation for Google BigQuery…Synthetic Consumers: The Promise, The Reality, and The Future
Synthetic consumers are AI-generated personas designed to simulate human consumer behavior. They are rapidly transforming market research by delivering faster, cost-effective, and highly scalable insights compared to traditional methods. By 2027, synthetic responses are expected to constitute over half of all market research data, highlighting the urgency for businesses to understand and adopt this technology strategically. This white paper equips technical business leaders, consumer insights experts, and data scientists with clear and actionable knowledge about this technology…Efficiency in the public sector: communication and co-ordination
I’ve been thinking a lot about efficiency in the public sector recently, particularly how we can improve it. In this post, I’ll focus on some ideas for improving communication and co-ordination between public sector workers…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #591 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~67,400 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian