
Data Science Weekly - Issue 604
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #604
June 19, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Guess the Correlation
How good are you at guessing correlation coefficients from scatter plots? Test your skills!…the aim of the game is simple. try to guess how correlated the two variables in a scatter plot are. The closer your guess is to the true correlation, the better…Guess the correlation is a game with a purpose. this means, while it aims to be entertaining, data on the guesses is collected and used to analyse how we perceive correlations in scatter plots. so the more people that play, the more data is generated!…
I built a game to simulate the life of a Chief Data Officer
[Originally on Reddit here] … You take on the role of a Chief Data Officer at a fictional company…Your goal : balance innovation with compliance, win support across departments, manage data risks, and prove the value of data to the business…All this happens by selecting an answer to each email received in your inbox…You have to manage the 2 key indicators : Data Quality and Reputation. But your ultimate goal is to increase the company’s profit…I counted all of the yurts in Mongolia using machine learning
The Fall of Civilizations podcast put out a 6¾-hour episode on the history of the Mongol Empire, which I eagerly listened to. After finishing the episode I wondered about contemporary Mongolian society, I wanted to learn what the lands that the Mongol Empire exploded from are like in our current day…I was curious: just how many yurts (ger in Mongolian) are in Mongolia and why? This set me on the path drawing bounding boxes on over 10,000 yurts to train a machine learning model to count the rest of the yurts in the country. While I was training the model, I wondered what the story behind these yurts are, I did a small investigation for later in this article. For now, this is the story of counting them…
Sponsor Message
Data Science Programs from Drexel University

Find your algorithm for success with a Master’s in Data Science from Drexel University. Gain essential skills in tool creation and development, data and text mining, trend identification, and data manipulation and summarization by using leading industry technology to apply to your career. Learn more.
.
.
* Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
What’s on your mind
This Week’s Poll:
Last Week’s Poll:
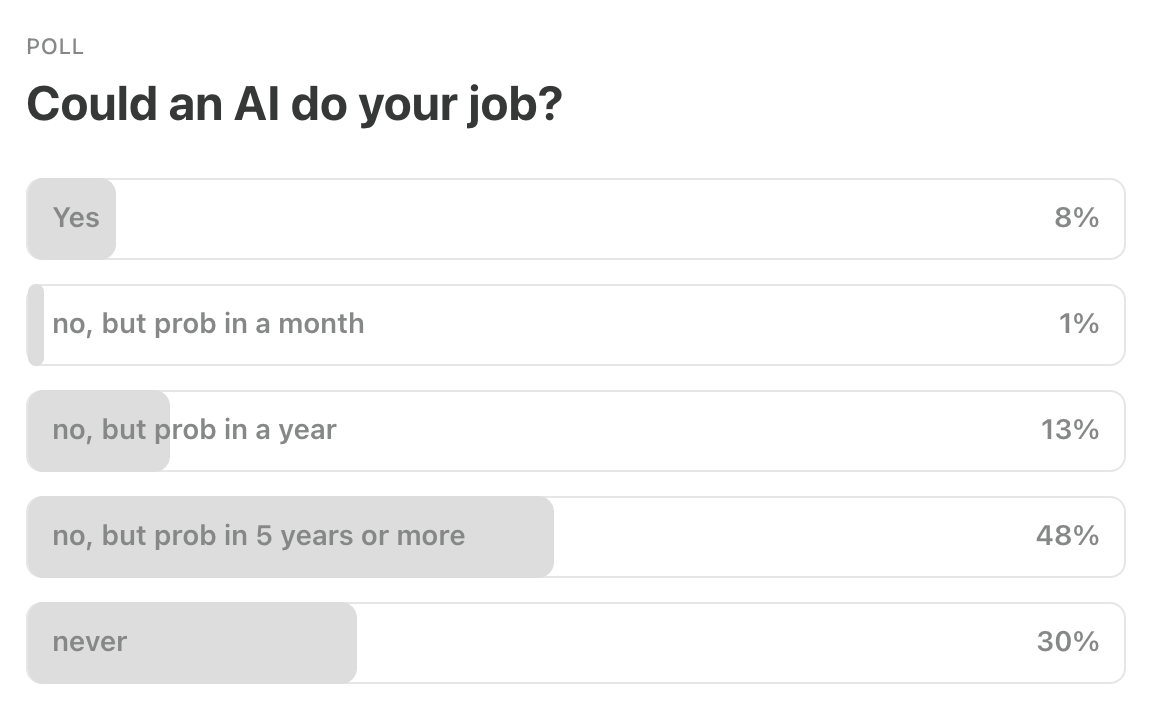
.
Data Science Articles & Videos
ClickHouse at OpenAI: Scaling ClickHouse to Petabytes of Logs
Akshay Nanavati and Poom Chiarawongse, Members of Technical Staff at OpenAI, share how the OpenAI observability team scaled ClickHouse as ChatGPT adoption, and log volume, skyrocketed…Pitfalls of premature closure with LLM assisted coding
This medical case study (above) illustrates “premature closure”: a cognitive error where physicians latch onto an initial diagnosis and fail to consider reasonable alternatives. In this case, the atypical presentation led multiple experienced doctors to anchor on the most probable explanation while nearly missing a critical, less common condition…The same pattern is emerging in software development as AI coding assistants become more sophisticated. The models are so good now that their first suggestion often looks not just plausible, but convincing. Professional formatting, clean code, proper naming conventions—everything appears right. And therein lies the trap: The allure of the perfect-looking solution…How to add a missing method to polars
My fav trick in polars is that you can monkeypatch anything you feel that is missing…It does rust under the hood, but because it's also Python you're still free to do whatever!…A universal foundation model for transfer learning in molecular crystals
Here we present Molecular Crystal Representation from Transformers (MCRT), a transformer-based model for molecular crystal property prediction that is pre-trained on 706 126 experimental crystal structures extracted from the Cambridge Structural Database (CSD). MCRT employs four different pre-training tasks to extract both local and global representations from the crystals using multi-modal features to encode crystal structure and geometry. MCRT has the potential to serve as a universal foundation model for predicting a range of properties for molecular crystals, achieving state-of-the-art results even when fine-tuned on small-scale datasets. We demonstrate MCRT's practical utility in both crystal property prediction and crystal structure prediction. We also show that model predictions can be interpreted by using attention scores…Writing documentation for AI: best practices
Retrieval-Augmented Generation (RAG) systems like Kapa rely on your documentation to provide accurate, helpful information. When documentation serves both humans and machines well, it creates a self-reinforcing loop of content quality: clear documentation improves AI answers, and those answers help surface gaps that further improve the docs…This guide provides best practices for creating documentation that works effectively for both human readers and AI/LLM consumption in RAG systems. Many best practices benefit both simultaneously, often in complementary ways…What underrated ML techniques are better than the defaults [Reddit]
I come from a biology/medicine background and slowly made my way into machine learning for research. One of the most helpful moments for me was when a CS professor casually mentioned I should ditch basic grid/random search and try Optuna for hyperparameter tuning. It completely changed my workflow, way faster, more flexible, and just better results overall. It made me wonder what other "obvious to some, unknown to most" ML techniques or tips are out there that quietly outperform the defaults? Curious to hear what others have picked up, especially those tips that aren’t widely taught but made a real difference in your work…Understanding and Coding the KV Cache in LLMs from Scratch
KV caches (a KV cache stores intermediate key (K) and value (V) computations for reuse during inference (after training), which results in a substantial speed-up when generating text) are one of the most critical techniques for efficient inference in LLMs in production. KV caches are an important component for compute-efficient LLM inference in production. This article explains how they work conceptually and in code with a from-scratch, human-readable implementation…The Rise and Fall of TV Sitcoms: A Statistical Analysis
In 1953, an episode of I Love Lucy that featured the birth of Lucy's son was watched simultaneously by approximately 71% of American households…surpassing the viewership of Eisenhower's presidential inauguration…Flash forward to today, when no narrative TV show captures more than 5% of American households at a time, and the sitcom format is in decline (and has been for decades)…So today, we'll explore the rise and fall of the TV sitcom, investigate the genres that have taken its place, and consider whether this beloved format is ripe for a revival…
Brazilians will soon be able to sell their digital data
Brazil is piloting dWallet, a project that lets citizens earn money from their data. It is ahead of similar U.S.-based initiatives…
Are Python Dictionaries Ordered Data Structures?
Order the boxes from smallest to largest…Stand in a queue in the order you arrived at the shop…You don't need me to define what the word "order" means in either of these instructions above. In Python, some data structures are ordered. Others aren't. So, what about dictionaries? Are they ordered?…
Model Once, Represent Everywhere: UDA (Unified Data Architecture) at Netflix
Core business concepts like ‘actor’ or ‘movie’ are modeled in many places: in our Enterprise GraphQL Gateway powering internal apps, in our asset management platform storing media assets, in our media computing platform that powers encoding pipelines, to name a few…Each system models these concepts differently and in isolation, with little coordination or shared understanding. While they often operate on the same concepts, these systems remain largely unaware of that fact, and of each other…we need new foundations that allow us to define a model once, at the conceptual level, and reuse those definitions everywhere. But it isn’t enough to just document concepts; we need to connect them to real systems and data. And more than just connect, we have to project those definitions outward, generating schemas and enforcing consistency across systems. The conceptual model must become part of the control plane. These were the core ideas that led us to build UDA (Unified Data Architecture)…Is there a Half-Life for the Success Rates of AI Agents?
Building on the recent empirical work of Kwa et al. (2025), I show that within their suite of research-engineering tasks the performance of AI agents on longer-duration tasks can be explained by an extremely simple mathematical model — a constant rate of failing during each minute a human would take to do the task. This implies an exponentially declining success rate with the length of the task and that each agent could be characterised by its own half-life. This empirical regularity allows us to estimate the success rate for an agent at different task lengths…R Package Quality: Validation and beyond!
As is often the case, it’s pretty easy to talk about “good” R packages. We can even wave our hands and talk about packages following “software standards” or “best practices”. But what does that mean?…Most of us would agree that packages like {Rcpp} or {dplyr} are solid. At the other end of the spectrum, we could point to outdated, poorly tested or unmaintained packages as “risky”. But the reality is that most R packages fall somewhere in between…However, the reality is considerably more nuanced: the vast majority of R packages exist somewhere along the continuum between these two extremes…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #603 here.
Cutting Room Floor
Andrej Karpathy: Software in the era of AI [video, link to HN discussion]
10 Learnings After a Year of Building AI Agents in Production
tiny-diffusion: A minimal PyTorch implementation of probabilistic diffusion models for 2D datasets
From superposition to sparse codes: interpretable representations in neural networks
.
Whenever you're ready, 3 ways we can help:
Want to get better at Data Science / Machine Learning Math? I have a zero weekly tutoring slots open. Hit reply to this email and let me know what you want to learn. I’ll add you to the waitlist.
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,400 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian