
Data Science Weekly - Issue 608
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #608
July 17, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
How to Build a Brain (without losing yours): Intro to Neuromorphic computing
I went deep into a neuromorphic computing rabbit hole recently and so this blog is an attempt at documenting everything I learnt and read about it. The goal is to be able to build a minimal brain-inspred model that is power efficient and can classify images. I’ve skipped the math and have written from an intuitive sense, with some code snippets…In this blog I cover:how the brain works from a neuroscience perpective
training SNN on the mnist dataset
calculating power efficiency of the model
why do SNNs work
neuromorphic hardware
Let’s start!
The Smartest Way to Orient a Solar Panel
How do we orient a solar panel to maximize energy harvesting in complex environments? I came across this recent research paper that answers this question. No LLMs, no foundation model, no machine learning, just good old simple math of convolution and the Fourier transform. It's SO COOL that I can't help but make an overview video…Reflections on OpenAI
I left OpenAI three weeks ago. I had joined the company back in May 2024. I wanted to share my reflections because there's a lot of smoke and noise around what OpenAI is doing, but not a lot of first-hand accounts of what the culture of working there actually feels like…Nabeel Qureshi has an amazing post called Reflections on Palantir, where he ruminates on what made Palantir special. I wanted to do the same for OpenAI while it's fresh in my mind. You won't find any trade secrets here, more just reflections on this current iteration of one of the most fascinating organizations in history at an extremely interesting time…
What’s on your mind
This Week’s Poll:
Last Week’s Poll:
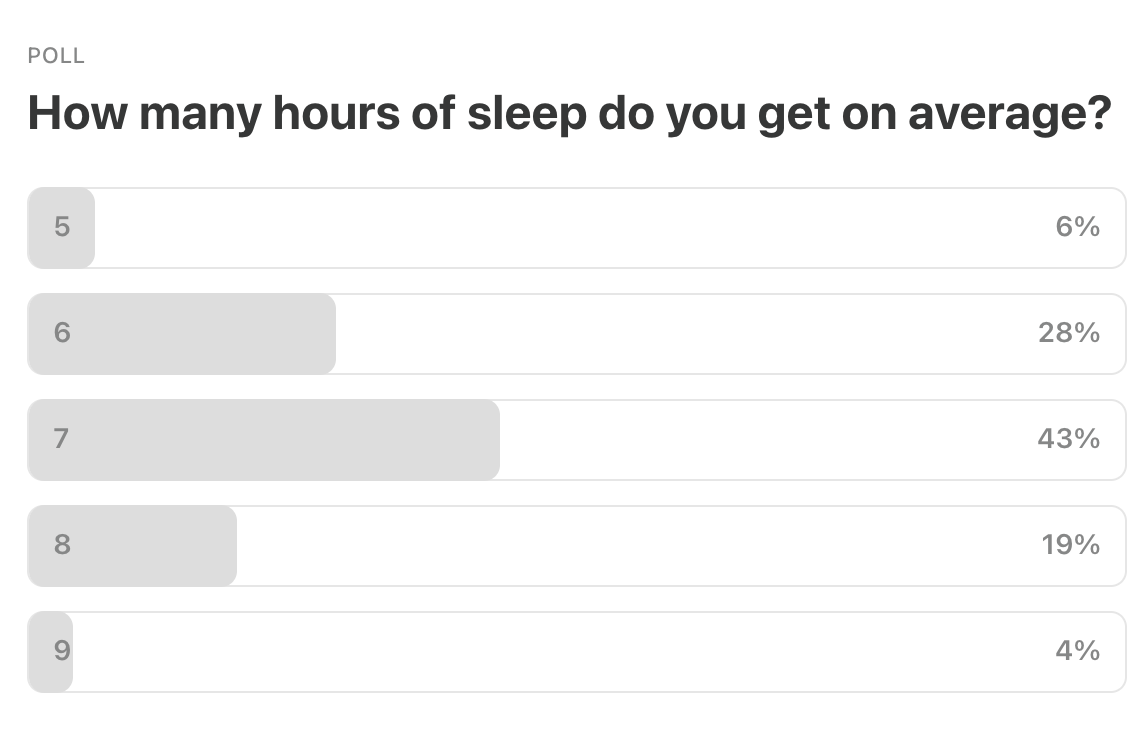
.
Data Science Articles & Videos
Proper handling of continuous variables is crucial in healthcare research, for example, within regression modeling for descriptive, explanatory, or predictive purposes. However, inadequate methods are commonly used. This article highlights the importance of appropriately handling continuous variables, and illustrates the consequences of categorization. This article also explains why assuming a linear relationship between the independent and dependent variable might be inappropriate, and describes how to use splines or fractional polynomials to model non-linear relationships….
What are the bottlenecks holding machine learning back? [Reddit]
I remember this being posted a long, long time ago. What has changed since then? What are the biggest problems holding us back?…Asymmetry of verification and verifier’s law
Asymmetry of verification is the idea that some tasks are much easier to verify than to solve. With reinforcement learning (RL) that finally works in a general sense, asymmetry of verification is becoming one of the most important ideas in AI…An Analysis of Elo Rating Systems via Markov Chains
We present a theoretical analysis of the Elo rating system, a popular method for ranking skills of players in an online setting. In particular, we study Elo under the Bradley--Terry--Luce model and, using techniques from Markov chain theory, show that Elo learns the model parameters at a rate competitive with the state of the art. We apply our results to the problem of efficient tournament design and discuss a connection with the fastest-mixing Markov chain problem…Could AI slow science? Confronting the production-progress paradox
Any serious attempt to forecast the impact of AI on science must confront the production-progress paradox. The rate of publication of scientific papers has been growing exponentially, increasing 500 fold between 1900 and 2015. But actual progress, by any available measure, has been constant or even slowing. So we must ask how AI is impacting, and will impact, the factors that have led to this disconnect. Our analysis in this essay suggests that AI is likely to worsen the gap…Learn Stan with brms, Part I
Though I’m an ardent brms user, I’ve been learning more about Stan for another project. One of the ways you can learn more about Stan is by reviewing the Stan code underlying your brms models. But I’m guessing that if you’ve ever tried that, you discovered Paul Bürkner’s Stan code can be challenging to read. The purpose of this post, and the next couple posts to come, is to help demystify the Stan code from a few simple brms models…Luxembourg’s Research Landscape: A Comprehensive Analysis of Scientific Publications
This report offers a detailed look at Luxembourg’s research output from 2015 to 2025. Using data from the OpenAlex database, it examines trends in scientific publications, key areas of research, international partnerships, and the impact of this research. The analysis distinguishes between work led by researchers in Luxembourg and projects where they contributed as international collaborators…Caching is an Abstraction, not an Optimization
I've always been told that caching is a tool to make software faster. That, given some careful considerations to consistency, caching makes it so that when you want to read a given piece of data, you don't have to go all the way back to some backend database or API server or SSD and can instead just read from some faster location like memory for the same data. Caching is thus a tool to improve performance…My feelings now are that that perspective on caching is wrong, or at least incomplete…
Become a machine learning engineer in five to seven steps
A couple of people slid into my Twitter DM’s asking for advice on how to become an ML Engineer. I am not Karpathy, but I am a solid mid-level machine-learning engineer, I became one by deliberate effort and my transition from hobbyist to professional happened only recently. If you want to follow a similar path, I want to provide you with an actionable roadmap and practical resources to pivot or build the foundation for your career. I hope my advice is useful…
Introducing Amazon S3 Vectors: First cloud storage with native vector support
Today, we’re announcing the preview of Amazon S3 Vectors, a purpose-built durable vector storage solution that can reduce the total cost of uploading, storing, and querying vectors by up to 90 percent…Amazon S3 Vectors is the first cloud object store with native support to store large vector datasets and provide subsecond query performance that makes it affordable for businesses to store AI-ready data at massive scale…
Making sense of academic statistics: notes on tenure and the relationship between statistics and data analysis
Academic statistics can seem counterintuitive and confusing to outsiders, and this post describes why. I describe what the field values and how those incentives shape the kind of work statisticians end up doing—and not doing. My goal is to clarify the sometimes opaque institutional dynamics between academic statistics, data analysis, and the production of scientific knowledge…Has anyone encountered a successful paper reading group at your company? [Reddit]
I work for a B2B ML company, ~200 people. Most of our MLEs/scientists have masters' degrees, a few have PhDs. Big legacy non-tech businesses in our target industry give us their raw data, we process it and build ML-based products for them. Recently we've started a paper reading group…Have you tried this at your company? How long did it last? How do you operate it?…From Raw Data to Citywide Insights: How Snowflake, dbt, and Airflow Work Together
I’ve always been curious about the city I live in, Jakarta. With more people moving in, air quality declining, infrastructure expanding, and traffic turning into chaos, I wanted to dig into the data to understand what was really happening…Using the CRISP-DM methodology, I built an end-to-end urban data pipeline powered by Snowflake, dbt, and Apache Airflow. The goal? To centralize urban data, track city expansion, and extract insights that could help shape better urban planning…In this article, I’ll take you through how I built this pipeline, the tools I used, and how this approach can scale for real-world city analysis…
.
Last Week's Newsletter's 3 Most Clicked Links
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
Vibe / Citizen Developers bringing our Datawarehouse to it's knees
.
* Based on unique clicks.
** Find last week's issue #607 here.
Cutting Room Floor
Welcome to DataRamen: A cozy web GUI for MySQL and PostgreSQL
Explore your Cloudflare data with Python notebooks, powered by marimo
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,400 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian