
Data Science Weekly - Issue 612
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #612
August 14, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
The Incompatibilities Between Generative AI and Art: Q&A with Ted Chiang
Ted Chiang's fiction has won four Hugo Awards, four Nebula Awards, six Locus Awards, and the PEN/Malamud Award and has been reprinted in The Best American Short Stories…In this talk, he expanded on points from his essay “Why A.I. Isn’t Going to Make Art” in The New Yorker (August 2024). To delve deeper into topics such as artistic self-expression and art’s requirement that the creator make all the choices, as well as the tension between art and commerce, we invited Chiang to respond to a set of questions related to AI and its impact on humanities scholarship…
A personal health large language model for sleep and fitness coaching
Here we introduce the Personal Health Large Language Model (PH-LLM), designed for applications in sleep and fitness. PH-LLM is a version of the Gemini LLM that was finetuned for text understanding and reasoning when applied to aggregated daily-resolution numerical sensor data…We are all genetic mutants
Over the past few years, a handful of trends have come together that will make it essential for every health-focused individual to know the handful of most important genetic variants in their genome – if you're the type of person who tests your LDL cholesterol every year or two, you'll also want to check for updates in our understanding of your unique genetic profile. These two trends are in two buckets – advances in understanding your genome and taking action…
What’s on your mind
This Week’s Poll:
.
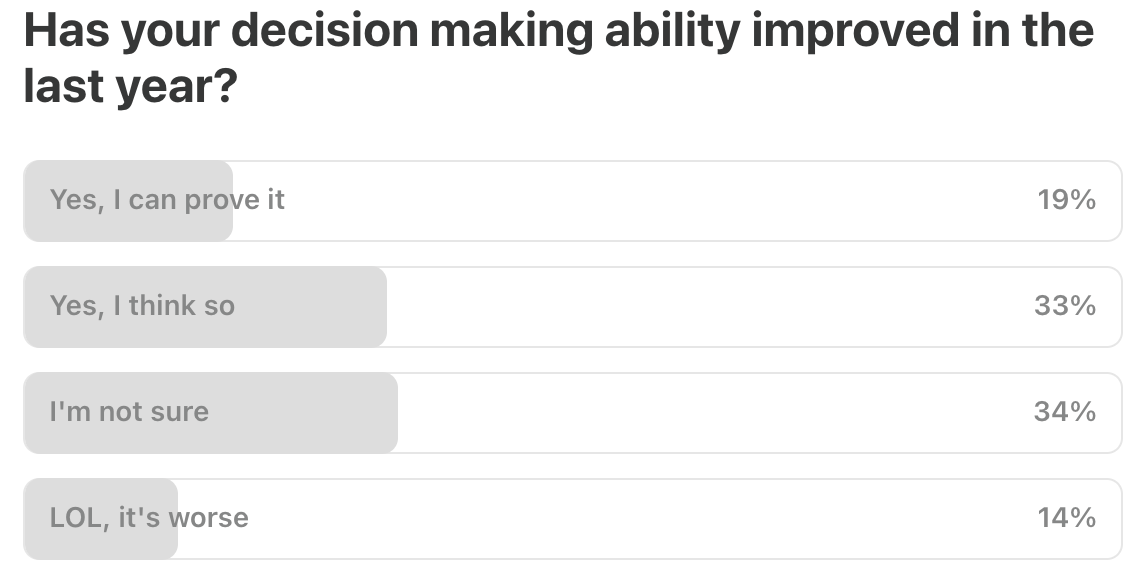
Last Week’s Poll:
.
Data Science Articles & Videos
A
ggplot2andgganimateVersion of Pac-ManThe story of ggpacman. Or how to build a useless but fun R package to make a GIF of the game Pac-Man…
People in ML/DS/AI field since 5-10 years or more, are you tired of updating yourself with changing tech stack? [Reddit]
I have been in this space since SAS, and its quite exhausting to update with every skill in the market to stay relevant especially if trying for a job switch and going through the interviews. Till how long can you keep studying and updating with the new trend and also even if you get in the boat there is so much stress at the work place in these sectors mainly because the leadership is from the management background and theres a lot of pressure for tech people to deliver…Although I love my field but I have got to thinking lately that Is it even worth it?..I Made A Real-Time C/C++/Rust Build Visualizer
Many software projects take a long time to compile. Sometimes that’s just due to the sheer amount of code, like in the LLVM project. But often a build is slower than it should be for dumb, fixable reasons. I’ve had the suspicion that most builds are doing dumb stuff, but I had no way to see it. So I’ve been working on a cross-platform tool to help speed up builds (you can try it, see below). It works with any build system or programming language…How to learn, use & improve a programming language as a community
Communities of practice are powerful spaces for learning, collaboration, and innovation—especially in the context of coding and data science. In this talk, I’ll share what I’ve learned from leading and supporting R communities, with concrete examples of strategies, content, and programs that encourage participation and skill-sharing…AI research interviews
A few weeks ago, I started a new job at OpenAI. This document describes my interview process, lessons learned and advice for you. If you’re reading this, I assume that you are on the job market or considering a career change, and at least tangentially interested in generative AI and Large Language Models…Building Reproducible Analytical Pipelines
This course is my take on setting up code that results in some data product. This code has to be reproducible, documented and production ready. Not my original idea, but introduced by the UK’s Analysis Function. The basic idea of a reproducible analytical pipeline (RAP) is to have code that always produces the same result when run, whatever this result might be. This is obviously crucial in research and science, but this is also the case in businesses that deal with data science/data-driven decision making etc. A well documented RAP avoids a lot of headache and is usually re-usable for other projects as well…How Narwhals brings Polars, DuckDB, PyArrow, & pandas together
Suppose you want to write a data science tool to do feature engineering. Your experience may go like this:- Expectation: you can focus on state-of-the art techniques for feature engineering.- Reality: you keep having to make you codebase more complex because a new dataframe library has come out and users are demanding support for it. Or rather, it might have gone like that in the pre-Narwhals era. Because now, you can focus on solving the problems which your tool set out to do, and let Narwhals handle the subtle differences between different kinds of dataframe inputs!..How can I gain business acumen as a data scientist? [Reddit]
I can build models, but can I build profits? That’s the gap I’m trying to close….Senior data scientists seem to connect their work to revenue, retention, or strategy with ease, while I still default to thinking in terms of accuracy and technical metrics. How did you learn to bridge that gap?…Did you focus on general business knowledge, industry-specific skills, or hands-on projects? I want to speak the “language of the business” so my work is not just technically solid but strategically impactful…
Database Sharding
Sharding is the process of scaling a database by spreading out the data across multiple servers, or shards. Sharding is the go-to database scaling solution for many large organizations managing data at petabyte scale…In this article, you'll learn how sharding works and considerations for designing a performant sharded database cluster. Along the way, you'll be able to interact with database cluster diagrams, giving you the opportunity to really let the concepts sink in via hands-on examples…Measures of Central Tendency for an Asymmetric Distribution, and Confidence Intervals
There are three widely applicable measures of central tendency for general continuous distributions: the mean, median, and pseudomedian (the mode is useful for describing smooth theoretical distributions but not so useful when attempting to estimate the mode empirically). Each measure has its own advantages and disadvantages, and the usual confidence intervals for the mean may be very inaccurate when the distribution is very asymmetric. The central limit theorem may be of no help. In this article I discuss tradeoffs of the three location measures and describe why the pseudomedian is perhaps the overall winner due to its combination of robustness, efficiency, and having an accurate confidence interval…
Underwhelmed by stats::reshape
When was the last time you used stats::reshape? Probably never, in the presence of {tidyr}’s pivot_* and {data.table}’s melt/dcast reshaping (aka pivoting) functions. A while ago, while perusing through the {data.table} vignettes, I learned about the reshape function. The {data.table} core team described it as “It is an extremely useful and often underrated function.”. As a member of the “dependency-frets” (as reshape is part of base R), I’ve been using it fairly since…DSPy MIPROv2 Configuration Explained
Understanding what happens inside DSPy optimizers can be challenging, especially when dealing with the optimizer’s complex Constructor and Compiler parameters and their interactions. This guide will help clarify the intricacies of MIPROv2 and enable you to configure parameters with predictable outcomes…Counting Words at SIMD Speed
I've written some progressively faster word counting programs. First, we'll start with Python, and then we'll drop down to C, and finally, we'll use single instruction, multiple data (SIMD) programming to go as fast as possible. The task is to count the words in an ASCII text file. For example, Hello there! contains 2 words, and my 1 GiB benchmark text file contains 65 million words…
.
Last Week's Newsletter's 3 Most Clicked Links
If I get laid off tomorrow, what's the ONE skill I should have had to stay in demand? [Reddit]
Context Engineering — A Comprehensive Hands-On Tutorial with DSPy
.
* Based on unique clicks.
** Find last week's issue #611 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Thanks for sharing the roadmap of math for machine learning!
Congrats on the OpenAI job hope it’s been good so far