
Data Science Weekly - Issue 615
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #615
September 04, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Answering the Age-Old Question: Is a College Degree Worth It?
Is a college degree worth it? This question has pervaded conversations from family dining tables to corporate board rooms to political pulpits for quite awhile in the United States. However, topics such as student loan forgiveness, state support for public institutions, higher costs of attendance, and return-on-investment have increasingly amplified the asking of this question throughout public and private discourse. In the next series of blog posts, we will explore data from a number of sources to help us better understand the issues surrounding this increasingly important question…
Memory Subsystem Optimizations
In this blog I wrote 18 blog posts about memory subsystem optimizations. By memory subsystem optimizations, I mean optimizations that aim at making software faster by better using the memory subsystem. Most of them are applicable to software that works with large datasets; but some of them are applicable to software that works with any data regardless of its size…Here is a list of all posts that we covered on Johnny’s Software Lab…Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First
Large Language Model (LLM) agents, acting on their users' behalf to manipulate and analyze data, are likely to become the dominant workload for data systems in the future…We argue that data systems need to adapt to more natively support agentic workloads. We take advantage of the characteristics of agentic speculation that we identify, i.e., scale, heterogeneity, redundancy, and steerability - to outline a number of new research opportunities for a new agent-first data systems architecture, ranging from new query interfaces, to new query processing techniques, to new agentic memory stores…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
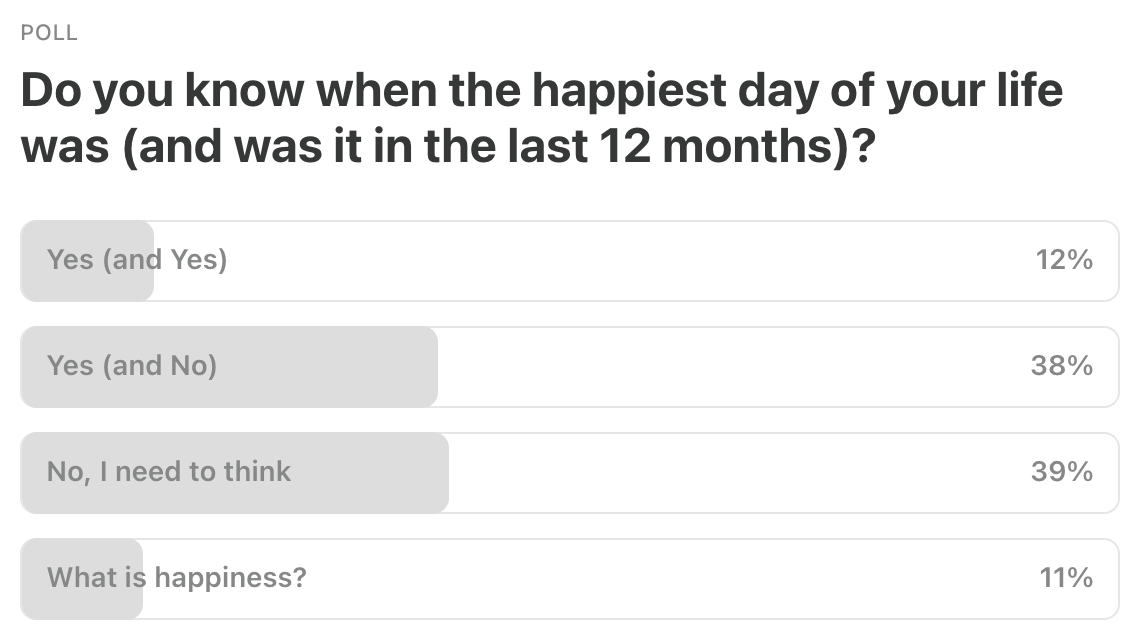
.
Data Science Articles & Videos
Learning Antimicrobial Resistance (AMR) genes with Bioconductor
I’ve always had a hard time learning and remembering all these genes for antimicrobial resistance (AMR). Yes, we can probably create some nice flash cards and try to memorize that way. But, why do the easy way when we can Rube Goldberg machine this! And use this as an opportunity to revisit Bioconductor and learn it! Let’s go!…What over-engineered tool did you finally replace with something simple? [Reddit]
We spent months maintaining a complex Kafka setup for a simple problem. Eventually replaced it with a cloud service/Redis and never looked back. What's your "should have kept it simple" story?…
Launch of Polars Cloud and Distributed Polars
After working hard since our Polars Cloud announcement last February, we are pleased to officially launch Polars Cloud. Polars Cloud is now Generally Available on AWS. Beyond that, we also launched our novel Distributed Engine in Open Beta on Polars Cloud…DSPy 0‑to‑1 Guide: Building Self‑Improving LLM Applications from Scratch
A comprehensive 0-to-1 guide for building self-improving LLM applications with DSPy framework…Understanding Multilevel Modeling
Multilevel modeling (also known as hierarchical linear modeling or mixed-effects modeling) extends the panel data framework to handle nested data structures that are ubiquitous in health research. While panel data considers observations across entities and time, multilevel models address situations where individual observations are nested within higher-level units, creating natural hierarchies in the data structure….Visual Story-Writing: Writing by Manipulating Visual Representations of Stories
We define "visual story-writing" as using visual representations of story elements to support writing and revising narrative texts. To demonstrate this approach, we developed a text editor that automatically visualizes a graph of entity interactions, movement between locations, and a timeline of story events. Interacting with these visualizations results in suggested text edits: for example, connecting two characters in the graph creates an interaction between them, moving an entity updates their described location, and rearranging events on the timeline reorganizes the narrative sequence….Data Lake Table Formats (Open Table Formats)
Data lake table formats serve as databases-like features on top of distributed File Formats. Similar to a traditional table, these formats consolidate distributed files into a singular table, simplifying management. Consider them an abstraction layer that structures your physical data files into coherent tables…The Bitter Lesson is Misunderstood
tl;dr: For years, we've been reading the Bitter Lesson backwards. It wasn't about compute — it was about data. Here's the part of Scaling Laws no one talks about: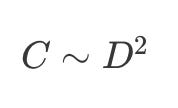
Translation: Double your GPUs? You need 40% more data or you're just lighting cash on fire. But there's no 2nd Internet (we’ve already eaten the first one). The path forward: data alchemists (high-variance, 300% lottery ticket) or model architects (20-30% steady gains), not chip buyers. Full analysis below…
A One-Page Primer on: Statistical Power
Statistical power is the chance to reject the null when it’s false. Why it matters, how to compute it, and why both researchers and readers should care. This is a one-page primer with rules of thumb and key readings…
Lessons on building an AI data analyst
I spent years on ML for Analytics and Knowledge Discovery at Google and Twitter. For the past 3 years I've been building an AI data analyst at Findly. We entered Y Combinator with a different idea, but quickly realised the real problem for most teams wasn't "lack of data" — it was data discovery and use…We, at Metabase, asked 338 teams in our community about how they build and use their data stacks, from tool choices to AI adoption, and built a community resource for data stack decisions in 2025…Some of our findings: - Postgres wins it all: #1 transactional DB and #1 analytics storage - 50% of teams skip warehouses/lakes - Data teams stay small: most are just 1-3 people, even at big companies - AI trust is shaky: average confidence only 5.5/10 There’s much more to see. Check it out..
Almost 2 years into my first job... and already disillusioned and bored with this career [Reddit]
I find this industry to be very unengaging, with most use cases and positions being very brainless, sluggish and just uninspiring. I am only 2 years into this job and bored and I feel like I need to shake things up a bit to keep doing this for the rest of my life…Data Engineering is Not Software Engineering
In recent years, it would appear that data engineering is converging with DevOps. Both have embraced cloud infrastructure, containerization, CI/CD, and GitOps to deliver reliable digital products to their customers. The convergence on a subset of tooling has led many to the opinion that there is no significant distinction between data engineering and software engineering. Consequently, the fact that data engineering is quite “rough around the edges” is simply because data engineers lag behind in the adoption of good software development practices…This assessment is misguided…
.
Last Week's Newsletter's 3 Most Clicked Links
The Most Important Machine Learning Equations: A Comprehensive Guide
How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
.
* Based on unique clicks.
** Find last week's issue #614 here.
Cutting Room Floor
Querying Billions of GitHub Events Using Modal and DuckDB (Part 1: Ingesting Data)
MDNS: Masked Diffusion Neural Sampler via Stochastic Optimal Control
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian