
Data Science Weekly - Issue 621
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #621
October 16, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
Sponsor Message
Online Data Science Programs from Drexel University

Find your algorithm for success with an online data science degree from Drexel University. Gain essential skills in tool creation and development, data and text mining, trend identification, and data manipulation and summarization by using leading industry technology to apply to your career. Learn more.
.
* Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
And now…let's dive into some interesting links from this week.
Editor's Picks
LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
Consumer research costs companies billions annually, yet suffers from panel biases and limited scale. Large language models (LLMs) offer an alternative by simulating synthetic consumers, but produce unrealistic response distributions when asked directly for numerical ratings. We present semantic similarity rating (SSR), a method that elicits textual responses from LLMs and maps these to Likert distributions using embedding similarity to reference statements. Testing on an extensive dataset comprising 57 personal care product surveys conducted by a leading corporation in that market (9,300 human responses), SSR achieves 90% of human test-retest reliability while maintaining realistic response distributions (KS similarity > 0.85)…
Robot Learning: A Tutorial
Robot learning is at an inflection point, driven by rapid advancements in machine learning and the growing availability of large-scale robotics data. This shift from classical, model-based methods to data-driven, learning-based paradigms is unlocking unprecedented capabilities in autonomous systems. This tutorial navigates the landscape of modern robot learning, charting a course from the foundational principles of Reinforcement Learning and Behavioral Cloning to generalist, language-conditioned models capable of operating across diverse tasks and even robot embodiments…To Explain or to Predict? [PDF]
The purpose of this article is to clarify the distinction between explanatory and predictive modeling, to discuss its sources, and to reveal the practical implications of the distinction to each step in the modeling process…
.
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
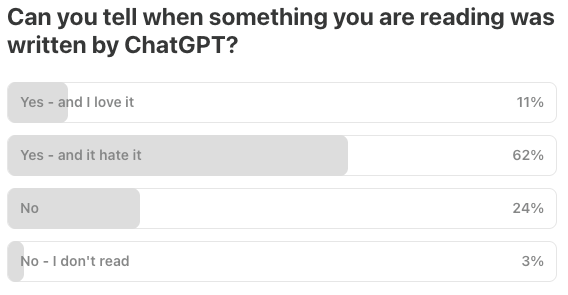
.
Data Science Articles & Videos
Why I’m not a fan of zero-copy Apache Kafka-Apache Iceberg
Over the past few months, I’ve seen a growing number of posts on social media promoting the idea of a “zero-copy” integration between Apache Kafka and Apache Iceberg. The idea is that Kafka topics could live directly as Iceberg tables. On the surface it sounds efficient: one copy of the data, unified access for both streaming and analytics. But from a systems point of view, I think this is the wrong direction for the Apache Kafka project. In this post, I’ll explain why…Am I the only one who spends half their life fixing the same damn dataset every month? [Reddit]
This keeps happening to me and it’s annoying as hell. I get the same dataset every month (partner data, reports, whatever) and like 30% of the time something small is different. Column name changed. Extra spaces. Different format. And my whole thing breaks…Then I spend a few hours figuring out wtf happened and fixing it. Does this happen to other people or is it just me with shitty data sources lol. How do you deal with it?…
Machine Learning in Chemistry: A Data Centred, Hands-on Introductory Machine Learning Course for Undergraduate Students
This course introduces fundamental ML algorithms using chemical datasets, such as the small molecule solubility dataset, and the peptide activity dataset. It progresses from traditional ML algorithms to neural networks, complemented by advanced modules on emerging topics such as reinforcement learning for retrosynthesis, ML-based force fields, deep learning for the predictions of protein structure and dynamics. By combining chemical context with hands-on coding and exposure to frontier applications, MLChem equips undergraduate chemistry students with both conceptual foundations and practical skills, preparing them to participate in ML-driven chemical research…Agent CI/CD Best Practices: Lessons From Monte Carlo’s Troubleshooting Agent
The unique CI/CD challenge for AI agents, as we quickly found out, is that they are non-deterministic. In other words, the same input can produce two different outputs. This means a traditional CI/CD framework leveraging tests with explicitly defined outputs doesn’t work for agentic systems…So we rethought CI/CD for agents from first principles. In this post we’ll share our learnings including a new key concept that has proven pivotal to ensuring reliability at scale…The Sovereign Tech Fund invests $450,000 in R Foundation to Enhance R’s Sustainability and Security
To understand the impact of this grant, we sat down with Simon Urbanek, a key member of the R Core Team and an Associate Professor in Statistics at the University of Auckland. Simon shared his insights on what this funding means for the future of R and how the community can play a part…Who Said Neural Networks Aren’t Linear?
Neural networks are famously nonlinear. However, linearity is defined relative to a pair of vector spaces, f : X → Y…Is it possible to identify a pair of non-standard vector spaces for which a conventionally nonlinear function is, in fact, linear? This paper introduces a method that makes such vector spaces explicit by construction…Scaling Request Logging from Millions to Billions with ClickHouse, Kafka, and Vector
How we solved request logging at scale by moving from MariaDB to ClickHouse, Kafka, and Vector after our deprecated database engine couldn’t keep up with billions of monthly requests…Geometric Deep Learning
As companion material to the release of our (proto-)book on Geometric Deep Learning, we have curated a series of blog posts. These blogs present a “digest” version of the key ideas covered by our work, as well as insight into how these ideas developed historically…So you want to build a data mesh
Data mesh is defined by its 4 core principles, which when applied can shift how data is managed organizationally, architecturally, technically, operationally, principally, and infrastructurally…We are going to explore these 4 principles through the lens of dbt, with the goal of outlining an opinionated approach to how you should architect your dbt Mesh of project(s). While dbt is extremely flexible in how it can be implemented, often a strong structure and grounding philosophy can be more helpful than endless possibilities…
AnyUp: Universal Feature Upsampling
We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training…we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks…Beads is a lightweight memory system for coding agents, using a graph-based issue tracker. Four kinds of dependencies work to chain your issues together like beads, making them easy for agents to follow for long distances, and reliably perform complex task streams in the right order…Drop Beads into any project where you’re using a coding agent, and you’ll enjoy an instant upgrade in organization, focus, and your agent’s ability to handle long-horizon tasks over multiple compaction sessions. Your agents will use issue tracking with proper epics, rather than creating a swamp of rotten half-implemented markdown plans…
Has anyone switched to AI Product Management from Data Science? [Reddit]
I’ve been a DS for almost 5 years, with a good majority in NLP. I’ve been wanting to do more POCs, less model production (IT budget, stack ranking, general burn-out) and get into Product Management for a while. I know the technology quite well, but I lack PM experience. Honestly, I’m pretty burnt out from DS. I really like working with cross-functional teams and focusing on strategy/business more so than coding…I’d love to know your journey and what made you stand out when making the switch!…IndexTables for Spark
IndexTables is an experimental open-table format for Apache Spark that enables fast retrieval and full-text search across large-scale data. It integrates seamlessly with Spark SQL, allowing you to combine powerful search capabilities with joins, aggregations, and standard SQL operations. Originally built for log observability and cybersecurity investigations, IndexTables works well for any use case requiring fast data retrieval…IndexTables runs entirely within your existing Spark cluster with no additional infrastructure…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #620 here.
Cutting Room Floor
Interview prep: What LeetCode questions were u asked for AI/MLE/Research scientist roles [Reddit]
gridmappr - an R package that automates the process of generating small multiple gridmap layouts
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian