
Data Science Weekly - Issue 629
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #629
December 11, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
The Girl Named Florida problem
The Monty Hall Problem is famously contentious. People have strong feelings about the answer, and it has probably started more fights than any other problem in probability. But there’s another problem that I think is even more counterintuitive – and it has started a good number of fights as well. It’s called The Girl Named Florida…the question is this:In a family with two children, what are the chances, if one of the children is a girl named Florida, that both children are girls?
If you have not encountered this problem before, your first thought is probably that the girl’s name is irrelevant – but it’s not. In fact, the answer depends on how common the name is…
How Google Maps quietly allocates survival across London’s restaurants - and how I built a dashboard to see through it
I wanted a dinner recommendation and got a research agenda instead. Using 13000+ restaurants, I rebuild its ratings with machine learning and map how algorithmic visibility actually distributes power…How Might We Learn?
Talks about learning technology often center on technology. Instead, I want to begin by asking: what do you want learning to be like—for yourself? If you could snap your fingers and drop yourself into a perfect learning environment, what’s your ideal? One way to start thinking about this question is to ask: what were the most rewarding high-growth periods of your life?…
.
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
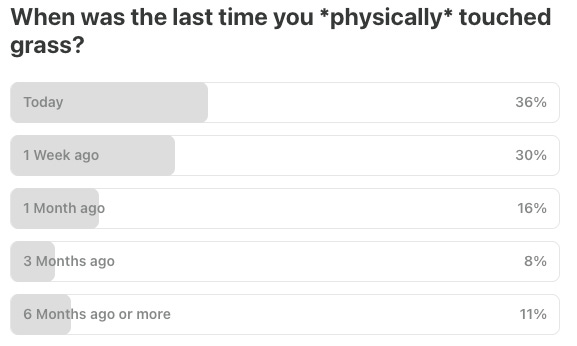
.
Featured Book
PROBABLY OVERTHINKING IT
Use Data to Answer Questions and Make Better Decisions
By Allen B. Downey, author of Think Python, Think Bayes, and Think Stats

Now in Paperback!
Think more clearly about data, avoid common statistical pitfalls, and make better decisions in an uncertain world.
Allen speaking about the book: “Probably Overthinking It” Google Talk
“It demands more intellectual engagement than a typical pop science book, drawing readers in with its broad scope of topics and colorful storytelling.”
Book Review by “Implicit Assumptions: “Probably Overthinking It” Book Review
Available from Bookshop.org and Amazon (affiliate links).
.
* Want to be featured in the newsletter? Email us for details --> team@datascienceweekly.org
Data Science Articles & Videos
Bad Data is a Feature
Incentives create bad data. Better priors are the workaround…When working for truth carries real personal downside and limited upside, people don’t lie, they round. They soften. They blur. They look elsewhere. They drift toward the version of reality that hurts them least…Will Pandas ever be replaced? [Reddit]
We’re almost in 2026 and I still see a lot of job postings requiring Pandas. With tools like Polars or DuckDB, that are extremely faster, have cleaner syntax, etc. Is it just legacy/industry inertia, or do you think Pandas still has advantages that keep it relevant?…
Haskell IS a Great Language for Data Science
I’ve been learning Haskell for a few years now and I am really liking a lot of the features, not least the strong typing and functional approach. I thought it was lacking some of the things I missed from R until I found the dataHaskell project…In this post I’ll demonstrate some of the features and explain why I think it makes for a good (great?) data science language…Saloni’s guide to data visualization
Why data visualization matters, and how to make charts more effective, clear, transparent, and sometimes, beautiful…Until a few years ago, I thought data visualization wasn’t very interesting. At best, it was a nice bonus in my work. I preferred writing because I found it gave me the space to get across the details and clarifications that people would often miss on a flashy chart…NeurIPS 2025 Day One: A QuantumBlack Perspective
In this post, we share their insights from the first day. Where is the research community heading? And how can organizations position themselves to translate this year’s learnings into sustainable competitive advantage?…We don’t know what most microbial genes do. Can genomic language models help?
This is an interview with Yunha Hwang, an assistant professor at MIT (and co-founder of the non-profit Tatta Bio). She is working on building and applying genomic language models to help annotate the function of the (mostly unknown) universe of microbial genomes…Growing an R Community in a Shifting Tech Landscape: The Story of R-Ladies Zurich
Luisa Barbanti, organizer of R-Ladies Zurich, shares how her team keeps a technically focused R community thriving in Switzerland as tools, workplaces, and expectations evolve. From meetup formats and speaker selection to mentorship and inclusion, she reflects on what it takes to grow a sustainable R community today…Data Visualization with R course’s last Class FAQs
Answering questions likeWhat kind of communities can I follow online to keep up with this R stuff?
Who in the R and dataviz world should I be following?
Will R ever be fully replaced by AI?
Why won’t you incorporate LLMs and AI prompting into the course?
and more…
Best practices for hiring data scientists (PyData Boston March 2025 Meetup)
Or: Data Science hiring is broken…how can we fix it?
Introduction to Stochastic Variational Inference with NumPyro
In this notebook we provide a brief introduction to Stochastic Variational Inference (SVI) with NumPyro. We provide the key mathematical concepts, but we focus on the code implementation. This introductory notebook is meant for practitioners. We do this by working through two examples: a very simple parameter recovery model and a Bayesian Neural Network…What Actually Makes You Senior
People love to describe senior engineers with a big checklist: architecture, communication, ownership, leadership, etc. But if you strip away the title, the salary, and the years of experience, there’s one core skill that separates senior+ engineers from everyone else: reducing ambiguity. Everything else flows from that. Here’s what I mean…
Traditional ML is dead and I’m pissed about it [Reddit]
Every single internship posting even for “Data Science Intern” or “ML Engineer Intern” is asking for GenAI, LLMs, RAG, prompt engineering, LangChain, vector databases, fine-tuning, Llama, OpenAI API, Hugging Face, etc….Like wtf, what happened?…I spent years learning the “fundamentals” they told us we must know for industry. And now?…None of it seems to matter.Statistical Rethinking (2026 Edition, 6 January to 13 March 2026)
First, I am doing live in-person lectures at MPI-EVA, but I will record lectures and make them available to the general public…This course teaches statistics, but it focuses on scientific models. The unfortunate truth about data is that nothing much can be done with it, until we theorize about what caused it. Therefore the meaning of any statistical estimate depends upon assumptions outside the data and statistical model. So we will prioritize these outside assumptions: causal models, how to analyze them, and how to use them to construct scientifically meaningful statistical procedures…This is not a theory course that focuses on theorems and proofs. It is a practical course that focuses on reliable and reproducible statistical workflow…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #628 here.
Cutting Room Floor
Building on PyTorch: Techniques for Extensibility and Innovation
Simulating data for Dirichlet regression with varying estimates
Comprehensive guide to the JAX AI Stack, centered on the Flax NNX library
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
That Google Maps article is super interesting