
Data Science Weekly - Issue 631
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #631
December 25, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
A framework for technical writing in the age of LLMs
In this post, I’ll externalize this thought process into a framework that I hope is useful for other folks like me who are writing technical content. Because so much writing is already being done by LLMs nowadays, I want to focus on what I believe humans can do better (with or without the help of LLMs), and to encourage folks to write more authentically…
Do you really need a lead scoring model?
One of the classic data science products in B2B is propensity models for lead scoring. Every company with a subscription product eventually asks the same question: which customers are most likely to buy our new thing?…After shipping a few of these, watching how they are actually used, and seeing which use cases got the most traction, I realized that the success of a propensity model has less to do with the model performance itself than with the economics of the channel it is plugged into…Google’s year in review: 8 areas with research breakthroughs in 2025
Here’s a look back at some of the breakthroughs, products and scientific milestones that defined the work of Google, Google DeepMind and Google Research in a year of relentless progress…
.
What’s on your mind
This Week’s Poll:
.
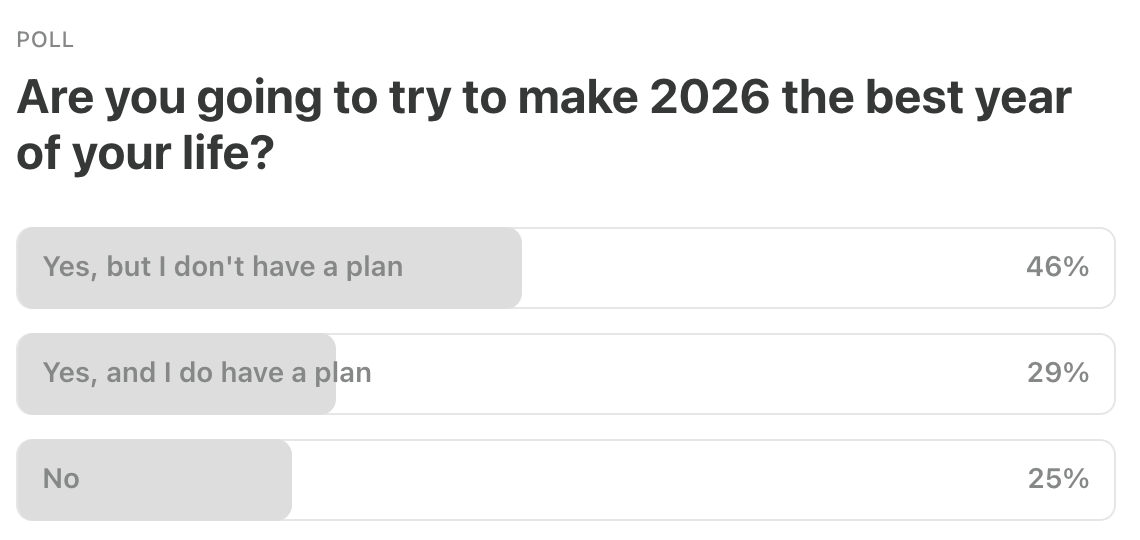
Last Week’s Poll:
.
Featured Book
PROBABLY OVERTHINKING IT
Use Data to Answer Questions and Make Better Decisions
By Allen B. Downey, author of Think Python, Think Bayes, and Think Stats

Now in Paperback!
Think more clearly about data, avoid common statistical pitfalls, and make better decisions in an uncertain world.
Allen speaking about the book: “Probably Overthinking It” Google Talk
“It demands more intellectual engagement than a typical pop science book, drawing readers in with its broad scope of topics and colorful storytelling.”
Book Review by “Implicit Assumptions: “Probably Overthinking It” Book Review
Available from Bookshop.org and Amazon (affiliate links).
.
* Want to be featured in the newsletter? Email us for details --> team@datascienceweekly.org
Data Science Articles & Videos
Why Apache Flink Is Not Going Anywhere
Astrologers proclaim the month of criticizing Apache Flink, I thought to myself recently. In the last few months, I have read many posts on social media, company blogs, and newsletters that attack Flink from different angles. So, today, I’d like to reply with this statement: Flink is not going anywhere…Realization that I may be a mid-level engineer at best [Reddit]
Feeling a bit demoralized today and wondering if anyone else has come to a similar realization and how they dealt with it…
Karpathy’s 2025 LLM Year in Review
2025 has been a strong and eventful year of progress in LLMs. The following is a list of personally notable and mildly surprising “paradigm changes” - things that altered the landscape and stood out to me conceptually…Three levels to compose R functions
Maybe few people who use R have forgotten already that R is functional by heart. R has Python dogma OO system, thanks to Reference Class (RC) and R6. R functions can be treated as Lisp’s macros, where it can let you meddle the function and abstract syntax tree (AST) of the function call…R has few ways to compose a function, divided by three (3) levels:Manual Typing
Higher-order Functions
Programmatic…
S3 server access logs at scale
In this post, we cover how we overcame storage and data management challenges, what worked (and didn’t work), and what we’ve learned operationalizing S3 logging at scale. We are excited to see how these capabilities will enable new workflows and improve our data security posture as we continue to gather more historical data…The Virtual Cell Will Be More Like Gwas Than Alphafold
There has been significant discussion recently on the concept of the “virtual cell.” I want to summarize the key concepts regarding what the field wants from a virtual cell and the challenges we face. In particular, the current trajectory reminds me of the evolution of statistical genetics (GWAS) and Mendelian disorders—analogies that I believe point to the most likely path for the field’s development…napari - multi-dimensional image viewer for python
napari is a fast, interactive, multi-dimensional image viewer for Python. It’s designed for browsing, annotating, and analyzing large multi-dimensional images. It’s built on top of Qt (for the GUI), vispy (for performant GPU-based rendering), and the scientific Python stack (numpy, scipy)…How to Build a Local ELT Pipeline with DuckDB and DBT
In this article, we are going to build a functional ELT (Extract, Load, Transform) pipeline using DuckDB (our analytical engine) and dbt (data transformation).Here is what we will cover:
The Architecture: Understanding the “Local Stack” approach.
The Ingestion: Using Python to load raw business data into DuckDB.
The Configuration: Setting up
dbt-duckdbto connect to our local database.The Transformation: Building specific data marts for Sales and Finance teams.
Let’s get started!…
Analyze Houston Garbage Collection 311 Calls
In the the past two months I have had to turn in three 311 tickets because our block got skipped on garbage day. I had not had a problem for several years prior to this year, so that sparked my curiosity and I decided to take a quick look at the data. This is that story….
Hack your way to a good Git history
I’ve now explained on this blog why it’s important to have small, informative Git commits and how I’ve realized that polishing history can happen in a second phase of work in a branch. However, I’ve more or less glossed over how to craft the history in a branch once you’re done with the work. I’ve entitled this post “Hack your way to a good Git history” because writing the history after the fact can feel like cheating, but it’s not!..Regression Modeling Strategies
All regression models have assumptions or constraints that must approximately hold for (1) findings from model-based analyses not to have alternate explanations, (2) statistical power to detect associations be optimized, (3) estimates about unknowns to have optimum precision, and (4) predictions to be accurate…There are four principal types of assumptions of regression models:
linearity of effects of predictors
additivity of effects of multiple predictors
absolute distributional assumptions
relative distributional assumptions…
Unix, R and python tools for genomics and data science
Unix, R and python tools for genomics and data science…Beer or Trdelnik or The Tale of Data in Computer Vision
What would a good assignment for the summer school in computer vision? That was the question I suddenly got puzzled with, because of the last minute replacement for another teacher I agreed to do for the Vision and Sports School…What would I like to get as a student? Something fun, probably related to the computer vision, but not your typical homework or coursework. Something light enough to have fun, but kind of useful. Something with a take-home message, but learned in personal experience, not written on a whiteboard…And what is the most important thing in the all machine learning? Of course, it is data. So…I have got an idea…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #630 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Regarding LLM technical writing, very astute points, though human nuance ramains tricky to define.