
Data Science Weekly - Issue 654
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #654
June 04, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let’s dive into some interesting links from this week.
Editor's Picks
How to Build a Simple, Bulletproof Data Pipeline
In most organizations, a lot of value can be delivered with a setup that avoids high costs and unnecessary complexity. The most common scenario is not real-time streaming or exotic architectures. It is daily extraction from one or more transactional systems backed by a relational database…In this article, I want to walk through a simple but realistic example and show how a few design decisions, even when they look basic, can make a meaningful difference in robustness, operability, and long-term maintainability…
AI for Bio has a Fuzzy API problem
“AI for bio” is getting hot again. Given the excitement in the current moment, I thought I’d share a bit about what actually makes biology uniquely hard as an application domain for machine learning. The reason is not simply that biology is complicated, though it obviously is. ML is good at many things that are complicated. The deeper reason is that drug discovery does not have the kind of clean feedback loops and clean interfaces that made modern ML so powerful elsewhere…Gaussian Point Splatting
We propose Gaussian point splatting, a stochastic method to render Gaussian splats that scales extremely well to scenes with many Gaussians. Our core idea is to sample pixel-sized, opaque points from the Gaussians and to splat them to a framebuffer using 64-bit atomics. Through parallel programming primitives, we achieve an even distribution of the workload across millions of threads…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
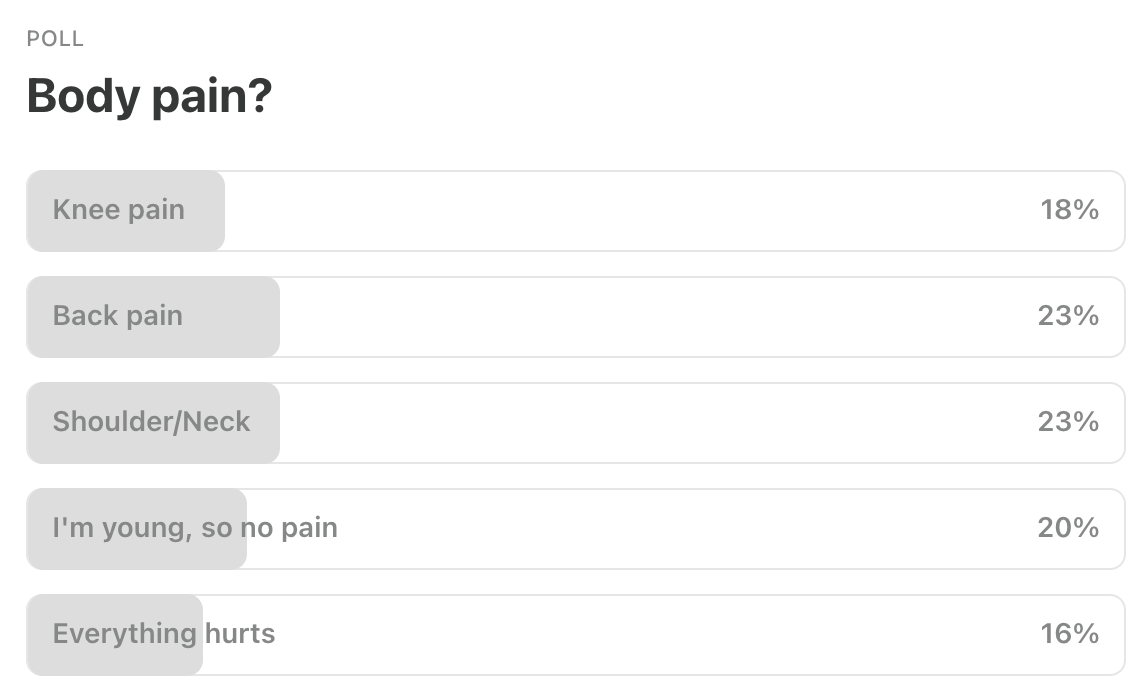
.
Data Science Articles & Videos
State of London Report, 2026
The State of London report brings together an array of data about how London is performing across its economy, society and environment. Published annually by the GLA’s City Intelligence unit, it provides an up‑to‑date, data‑led picture of life in the capital, drawing on a wide range of official and administrative sources. The report highlights trends and patterns and offers a shared evidence base to support debate and decision making…What is considered basic R? [Reddit]
I have a job interview coming up and they want someone who knows basic R, I think I do have it, but what is your opinion on what it entails?…
BRIDGE (Benchmark of Regional & International Data for Global Evaluation) is the first independent Global South ASR benchmark
BRIDGE (Benchmark of Regional & International Data for Global Evaluation) is the first independent Global South ASR benchmark evaluating 15 global models across 22 languages on a first-of-its-kind 7 metric stack…supertree - Interactive Decision Tree Visualization
supertreeis a Python package designed to visualize decision trees in an interactive and user-friendly way within Jupyter Notebooks, Jupyter Lab, Google Colab, and any other notebooks that support HTML rendering. With this tool, you can not only display decision trees, but also interact with them directly within your notebook environment. Key features include:ability to zoom and pan through large trees,
collapse and expand selected nodes,
explore the structure of the tree in an intuitive and visually appealing manner…
A Primer in Post-Training Reasoning Data: What We Know About How It Works
Work on post-training reasoning data has grown rapidly, yet this literature remains scattered across dataset papers, reinforcement-learning recipes, reward-model studies, benchmarks, and frontier system reports. This paper is the first primer to synthesize over 150 key public studies and system reports on post-training reasoning data. We organize the field around four questions: what data objects exist, what makes them useful, how they are constructed, and how they scale. Together, this organization provides an attribution framework for future reasoning-data releases and post-training recipes…
Don’t know where your data is from? Bayesian modeling for unknown coordinates
An especially strong motivating case for the usage of spatial probability models comes from the mining industry. During exploration for mineral resources, prospectors will take geologic samples by drilling holes and examining the resulting material for presence or concentration of valuable ores. These data typically show strong spatial correlation, but constructing a fully-detailed geophysical model is at times infeasible as we are able to observe very little of the underground conditions, though the advent of remote sensing techniques like ground-penetrating radar and gravimetry has dramatically improved our ability to characterize Earth’s subsurface. To address this challenge, we would like to construct a probability model which uses nearby data to predict a variable of interest at a new location…Why I think panic about local impacts of data centers is just a panic
In the last year of following increased local resistance to data centers being built, I’ve listened to lots of recorded testimony at town halls, read through countless comments and articles where people argue for why data centers are so uniquely evil and shut down anyone defending them as shills for AI companies…whenever I look into where people are actually getting their ideas about the hundreds of other data centers being built, the source always leads back to some confused misreading of local reporting, a wild calculation error, a bad game of telephone, or a wildly misleading article…Beyond the Semantic Layer: Building a Context Layer for the Agentic Era
A context layer puts your warehouse schema, joins, metric definitions, and business knowledge in one reviewable place so data agents query governed context instead of guessing field names. A look at how it works, and at ktx, the open-source context layer…How different are two discrete or binned probability distributions on the same support?…
Fluid Simulation for Dummies
I wrote my Master’s thesis on high-performance real-time 3D fluid simulation and volumetric rendering. The basics of the fluid simulation that I used are straightforward, but I had a very difficult time understanding it. The available reference materials were all very good, but they were a bit too physics-y and math-y for me. Unable to find something geared towards somebody of my mindset, I’d like to write the page I wish I’d had a year ago. With that goal in mind, I’m going to show you how to do simple 3D fluid simulation, step-by-step, with as much emphasis on the actual programming as possible….A Hitchhiker’s Guide to ML Training Infrastructure
Hardware has made a huge impact on the field of machine learning (ML). Many of the ideas we use today were published decades ago, but the cost to run them and the data necessary were too expensive, making them impractical. Recent advances, including the introduction of graphics processing units (GPUs), are making some of those ideas a reality. In this post we’ll look at some of the hardware factors that impact training artificial intelligence (AI) systems, and we’ll walk through an example ML workflow….
Weaponized phrases in Data science Teams [Reddit]
“No free cycles” / “Empty plates”…“We need to focus on the low-hanging fruit”…"Be a go-getter, don't get stuck"…"Let's optimize our sprint velocity"…“You’re making this more complicated than it is”…"We need to relentlessly prioritize"…"I need you to own this initiative"…"Let's take this offline" / "Parking lot this"…"We need to leverage AI to unlock enterprise value"…"We're like a family here"…Agricultural Field Boundaries, Mapped Globally for the First Time
For the first time, every agricultural field on Earth has a boundary on the map. Taylor Geospatial funded and co-developed this work with Microsoft AI for Good Lab because we believe GeoAI should work everywhere, not just in the data-rich regions where labeled training data is abundant. Today, it’s publicly available for everyone to benefit from…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #653 here.
Cutting Room Floor
.
Whenever you're ready, 3 ways we can help:
Go deeper each week (paid subscription)
Get 3 additional posts per week designed to help you:Statistics → understand the math behind ML
AI Agents → build with modern AI tools
Career → become more valuable at your job
Looking to get a job?
A practical guide to landing your first (or next) data science role, based on thousands of reader questions.
👉 Check out our “Get A Data Science Job” CoursePromote your organization/project/event to ~68,500 subscribers
Sponsor this newsletter and reach a highly engaged data science audience (30–35% open rate).
👉 Reply to this email to learn more
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian