
Data Science Weekly - Issue 656
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #656
June 18, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let’s dive into some interesting links from this week.
Editor's Picks
Free SQL→ER diagram tool, runs in the browser, nothing uploaded
Paste a SQL schema (CREATE TABLE statements) → get a clean, interactive ER diagram. Open source and 100% local — it runs entirely in your browser, so your schema never leaves your machine. No server, no signup, no upload…
Preschoolers search semantic networks in a broader and more variable way than adults: Implications for hypothesis generation
We find that adults show greater dependencies between sequential guesses than preschoolers, and generate a less diverse set of options. These findings may support the idea that development can be viewed as analogous to simulated annealing strategies in machine learning that start “hot” (in early childhood), generating wider and more variable searches, and eventually cool (in adulthood) to generate narrower searches…New CRAN Packages: signal or noise?
CRAN continues to be the most accessible repository for statistical knowledge on the planet, and the number of new packages being accepted by CRAN is growing faster than ever. But, is the R community really benefiting from this new growth?…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
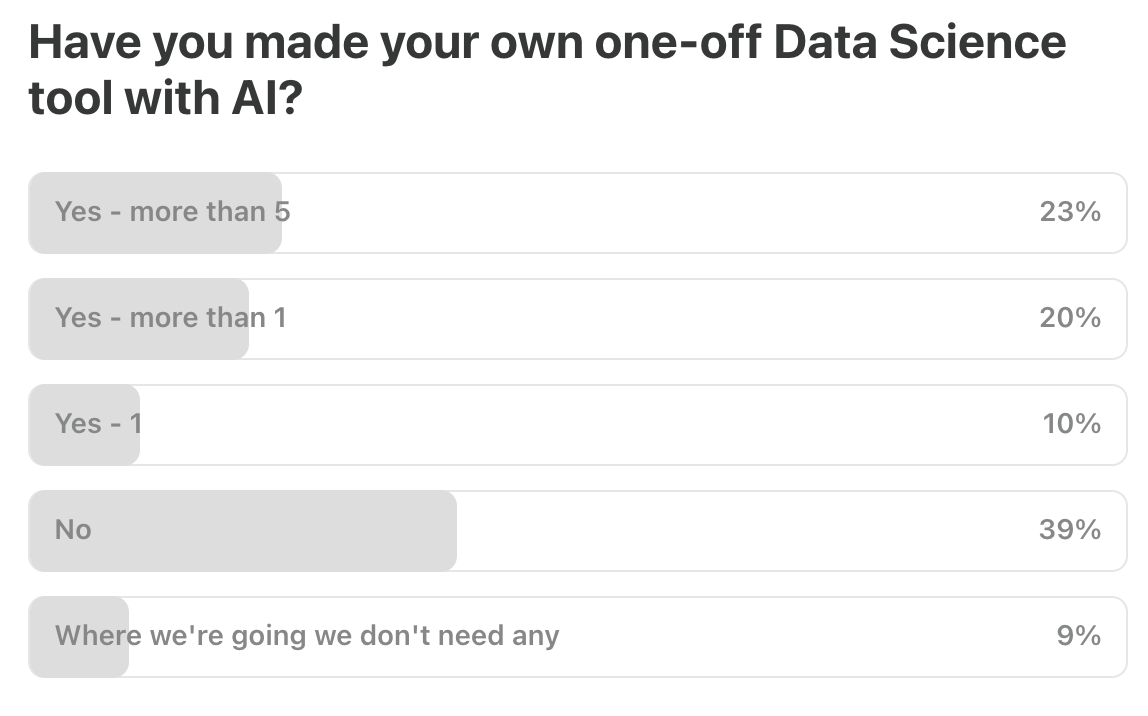
.
Data Science Articles & Videos
The 90-year-old idea behind JEPA models: Canonical Correlation Analysis (CCA)
Harold Hotelling’s 1936 Canonical Correlation Analysis (CCA) [modern terminology, “CCA is used to find a common signal among two large matrices”] forms the theoretical and intuitive foundation for modern embedding prediction techniques, including JEPA models…2026 Data Science Tech Stack at your Job [Reddit]
What is your current tech stack at your job?
A Beginner’s Guide to Robotics Hardware
Building an open-source robot begins in a way that is familiar to assembling IKEA furniture…The similarity ends once the robot is powered on. A bookshelf is designed to stay exactly as assembled, whereas a robot has to move while remaining correct about its own position and the state of its surroundings…When designing and building robots, this need for correctness both numerically and temporally is a key consideration…The rest of this post looks at how that difference manifests, using a common framing in robotics that divides the hardware into three parts: the movement, the body, and the sensor…PyData London 2026 Talks
All the talks from the PyData London 2026 are now available…Data Engineering Acquisitions (2022-2026)
Consolidation in the Data Engineering market is happening quickly. Tools from the Modern Data Stack get unified into bigger Data Platforms. This note highlights the latest acquisitions across data engineering. It serves as an overview of the latest consolidations. Find attached the acquisition overview from 2022 to today…
The software industry: annealing, but wrong
In recent months I’ve heard of several teams with an interesting policy: each pull request should be no more than a few files, and no more than a certain number of lines (say 500). And do just one thing and do it well. And be easy for a human to review. And be fully tested by the test suite…And often, the results are good. Sure, splitting a single 6000-line feature or fix into twelve 500-line PRs is more work, but each of those PRs is surely easier to review. And you can git bisect them when there’s a bug! And maybe revert the individual change that broke something. ...and also cause 12x as many context switches for your reviewers as they review each one sequentially. But that’s just the cost of software quality! Right?…AI and Survey Sampling Problems
My previous post discussed the performance of the artificial intelligence (AI) interface Gemini on undergraduate statistics problems. Now let’s look at how Gemini answers some of the problems in my sampling textbook (Lohr, 2022), and talk about how Gemini could help students learn sampling…Test Doubles Taxonomy for R: Dummy, Stub, Spy, Mock, Fake
You might call them all “mock”…Mock the database. Mock the API. Mock the function. The word becomes a catch-all for any test double, any object you substitute for a real dependency in a test. Lumping them together makes it harder to choose the right tool, and the wrong choice leads to brittle, misleading tests. There are five distinct types, each with a specific job. Knowing which is which is how you stop writing tests that do the wrong thing…A Brownian Motion (BM), without the “fractional” part, is a motion where the position of a given object over time changes in random increments…A Fractional Brownian Motion is a similar process in which the increments are not completely independent from each other, but there’s some sort of memory to the process…I believe fBM is not necessarily a well understood mechanism. So this article describes how it functions and their different spectral and visual characteristics for various values of their main parameter H, backed with some experiments and measurements…
Running local models is good now
I’ve been working with local models since they came out, and finally, they’re surprisingly good now…Snapshot Testing in R: Beyond Screenshots
In this post I want to walk through using snapshot testing for what it is good for, and the practices that make it efficient…
What algorithm is surprisingly new? [Reddit]
Other than any AI stuff, I’m talking about the types of algorithms you learn about in any standard Data Structures and Algorithms University course…I’m surprised that alot of these algorithms were actually invented HUNDREDS of years ago…The Ghost Couple: Correlated LLM Name Priors and Their Haunting of the Web and Academic Publishing
These names do not exist. Elena Vasquez and Marcus Chen have appeared as volcano experts, astronauts, thriller protagonists, podcast hosts, and academic co-authors across hundreds of independently produced AI-generated documents, never having lived. We show that llms do not merely default to high-probability individual names when generating fictional experts: they produce correlated character ensembles, pairs and trios whose co-occurrence rates far exceed chance and are consistent across independent generations. These priors are model-family-specific (Claude: Elena Vasquez + Marcus Chen + Amara Okafor; Gemini: Aris Thorne + Lena Petrova; GPT: Elara Voss with no fixed partner)…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #655 here.
Cutting Room Floor
Learning Amino Acids Part 1: Non-Polar Amino Acids, Rodrigues Rotation, and Lennard-Jones Potential
Gambling provides a gentle rocking of the emotions to put you in a pleasant baby-like state
.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian