
Data Science Weekly - Issue 605
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #605
June 26, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
The Bitter Lesson is coming for Tokenization
As it's been pointed out countless times - if the trend of ML research could be summarised, it'd be the adherence to The Bitter Lesson - opt for general-purpose methods that leverage large amounts of compute and data over crafted methods by domain experts…In this post, we highlight the desire to replace tokenization with a general method that better leverages compute and data. We'll see tokenization's role, its fragility and we'll build a case for removing it. After understanding the design space, we'll explore the potential impacts of a recent promising candidate (Byte Latent Transformer) and build strong intuitions around new core mechanics…
Optimizing SQL (and DataFrames) in DataFusion, Part 1: Query Optimization Overview
Sometimes Query Optimizers are seen as a sort of black magic, “the most challenging problem in computer science,” according to Father Pavlo, or some behind-the-scenes player. We believe this perception is because:One must implement the rest of a database system (data storage, transactions, SQL parser, expression evaluation, plan execution, etc.) before the optimizer becomes critical5.
Some parts of the optimizer are tightly tied to the rest of the system (e.g., storage or indexes), so many classic optimizers are described with system-specific terminology.
Some optimizer tasks, such as access path selection and join order are known challenges and not yet solved (practically)—maybe they really do require black magic 🤔.
However, Query Optimizers are no more complicated in theory or practice than other parts of a database system, as we will argue in a series of posts…
Machine Learning Visualized
Book of Jupyter Notebooks that implement and mathematically derive machine learning algorithms from first-principles. The output of each notebook is a visualization of the machine learning algorithm throughout its training phase, ultimately converging at its optimal weights…
What’s on your mind
This Week’s Poll:
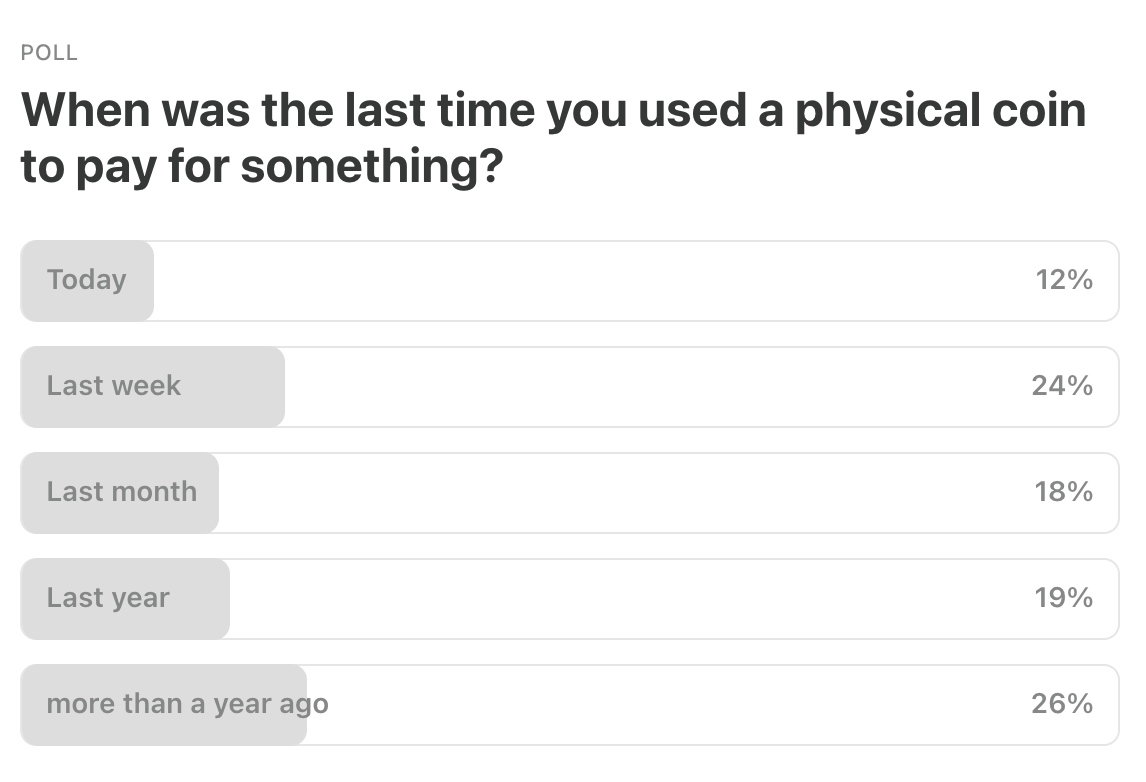
Last Week’s Poll:
.
Data Science Articles & Videos
loo R package 10 years!
loo is an R package that allows users to compute efficient approximate leave-one-out cross-validation for fitted Bayesian models, as well as model weights that can be used to average predictive distributions…Here’s a blog post about the background, advances during the years, and a bit about the future…Is it true that most of AI is just data cleaning and not fancy models? [Reddit]
I’ve been reading about how in real-world AI, most of the work isn’t the cool stuff like neural nets, but actually just getting the data usable. Things like cleaning missing values, feature engineering, and framing the problem right. Some people also said prompt engineering is the “new programming,” especially with LLMs becoming so dominant. I came across a blog that listed 10 things you only realize after starting with AI — like how feedback loops can mess up your model after deployment, or how important it is to define your objective before even touching code. It kinda shifted my view on what matters early on. Is this the general consensus? Or is it still more about algorithms in practice?…Automatic differentiation
These are rough notes for my PhD course on automatic differentiation. On the website you can find accompanying slides and notebooks. The reference book is [BR24], and most of the material below is adapted from there…When the Model Isn’t the Problem: How Data Gaps Undermine AI Systems
In this article, we’ll examine an internal case study involving our own troubleshooting agent to demonstrate why data quality is one of the biggest risks to production AI—and why you need end-to-end observability to solve it…RDM Weekly is a roundup of Research Data Management resources
I am so excited you are here and I look forward to sharing research data management resources with you every Tuesday! It was very tough choosing which resources to include in this inaugural newsletter. If anything though, this hopefully should indicate to you that there are MANY more great resources to come in future newsletters so definitely consider subscribing so you don’t miss out!…Introducing: the marimo-quarto plugin!
You can now use marimo with quarto from posit_pbc ! With the marimo-quarto plugin you get reactive execution as well as our suite of widget are all available from blogs that want to use it…I have run DS interviews and wow! [Reddit]
Hey all, I have been responsible for technical interviews for a Data Scientist position and the experience was quite surprising to me. I thought some of you may appreciate some insights…Gaussian Processes and Reproducing Kernels: Connections and Equivalences
This monograph studies the relations between two approaches using positive definite kernels: probabilistic methods using Gaussian processes, and non-probabilistic methods using reproducing kernel Hilbert spaces (RKHS). They are widely studied and used in machine learning, statistics, and numerical analysis. Connections and equivalences between them are reviewed for fundamental topics such as regression, interpolation, numerical integration, distributional discrepancies, and statistical dependence, as well as for sample path properties of Gaussian processes…
Advancing Low Earth Orbit: Achievements and Lessons from the DARPA Blackjack Program
The Defense Advanced Research Programs Administration (DARPA) Blackjack program, initiated with the goal of integrating advancements from the commercial sector in Low Earth Orbit (LEO), emphasizes cost savings through the miniaturization of space systems and lower launch costs…this paper delves into some of the mission successes identified during the operational phase of the program, these include constellation phasing and constellation control, demonstration of the utility of the Optical Inter-Satellite Communications system in the Space-toground and space-to air domain…
ggplot2 4.0.0 is coming and why ultimately it’s on YOU to ensure your environments are reproducible
It looks like a major update to {ggplot2} is coming (version 4.0.0), where Posit is switching the internals from S3 to S7. This will break many reverse dependencies of {ggplot2} (a reverse dependency is a package that depends on {ggplot2}), and so Posit is following the recommendation of the CRAN policies, which state that they should give a heads-up to devs of reverse dependencies and give them enough time to fix their packages. Posit even goes beyond that and is opening PRs to offer fixes themselves, which I think is really great…
Evaluating Long-Context Question & Answer Systems
In this write-up, we’ll explore key evaluation metrics, how to build evaluation datasets, and methods to assess Q&A performance through human annotations and LLM-evaluators. We’ll also review several benchmarks across narrative stories, technical and academic texts, and very long-context, multi-document situations. Finally, we’ll wrap up with advice for evaluating long-context Q&A on our specific use cases…What are the “hard” topics in data engineering? [Reddit]
What’s a “hard” topic in data engineering that could lead to a good career?…DSPy Real-World Examples
This section demonstrates practical applications of DSPy across different domains and use cases. Each tutorial shows how to build production-ready AI systems using DSPy's modular programming approach…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #604 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,400 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian