
Data Science Weekly - Issue 609
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #609
July 24, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Revisiting Moneyball: Data, sports, payrolls, and memes
In this post, I’ll go over the author’s intentions for writing the book, followed by popular critiques of Moneyball. The goal is to address some of the recurring debates as we cover the main themes and provide historical context for each…
The Economics and Physics of 100 TB daily telemetry data
We frequently come across north of 100 TB telemetry data generated on a daily basis…Such scale invites questions about the cost of ingestion, storage, query and retention of data. So, we wanted to dive deeper into the physics and economics behind ingesting 100 TB telemetry data daily, retaining it for 30 days and querying it actively. While economics will help understand the actual cost of software and hardware, Physics allows us to understand the instance types, the network bandwidth, disk I/O required. In this blog, we dive into our test setup, the client and server instances, load generation setup and query setup. Finally, we’ll cover the overall cost incurred on AWS in actuals…Where Physics Meets Behavior in Animal Groups
This review explores the critical role of the physics of the body and the environment in shaping behaviors within the emerging field of the physics of social interactions. We revisit the intriguing case study where a dead fish, lacking neural control, appeared to swim upstream, propelled by its body resonating with vortices…
What’s on your mind
This Week’s Poll:
Last Week’s Poll:
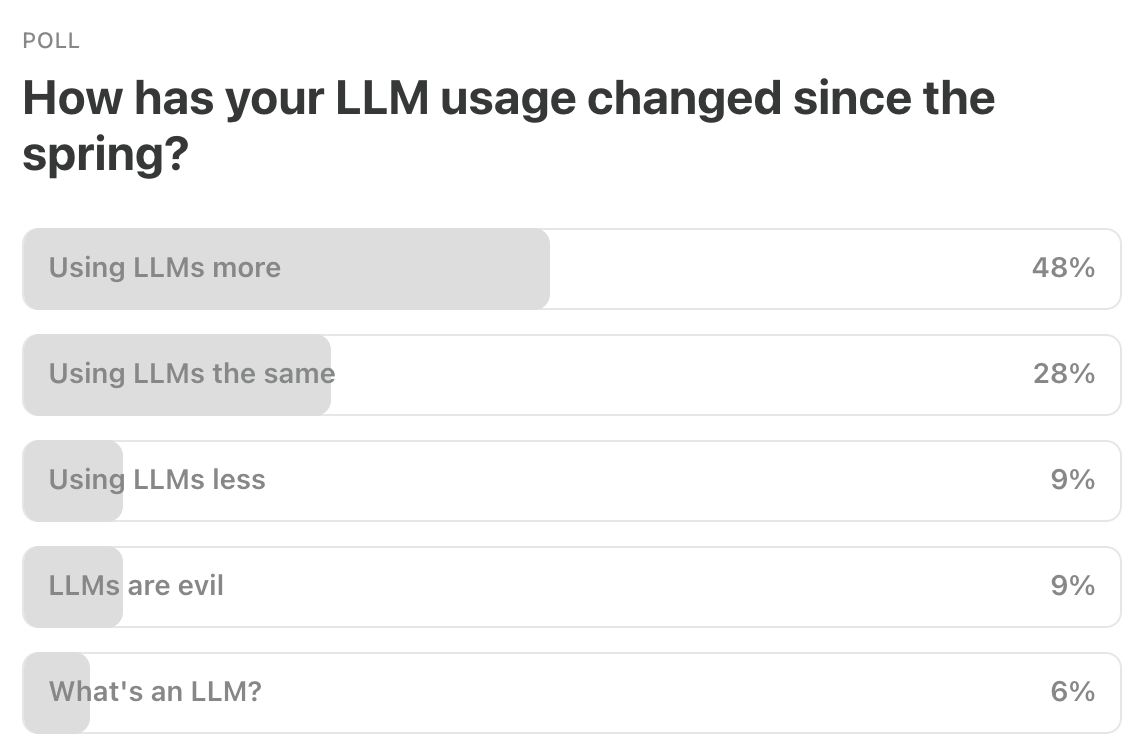
.
Data Science Articles & Videos
Hyparquet: The Quest for Instant Data
This is the story of how I spent a year making the world's fastest Parquet loader in JavaScript. The goal:
Make a faster, more interactive viewer for AI datasets (which are mostly parquet format)
Simplify the stack by doing everything from the browser (no backend)
TLDR: My open-source library Hyparquet can load data in 155ms, which would take 3466ms in duckdb-wasm for the same file…
So are we just supposed to know how to get a promotion? [Reddit]
I’ve been working as a Data Scientist I at a Fortune 50 company for the past 3.5 years. Over the last two performance cycles, I’ve proactively asked for a promotion. The first time, my manager pointed out areas for improvement—so I treated that as a development goal, worked on it, and presented clear results in the next cycle.,,However, when I brought it up again, I was told that promotions aren’t just based on performance—they also depend on factors like budget and others in the promotion queue. When I asked for a clear path forward, I was given no concrete guidance…Now I’m left wondering: until the next cycle, what am I supposed to do? Is it usually on us to figure out how to get promoted, or does your company provide a defined path?…Copy the Pros: How to Recreate this NYTimes Chart in R
Want to level up your data visualization skills? In this tutorial, I walk through how to use R to recreate a chart originally published by The New York Times…Postgres to ClickHouse: Data Modeling Tips V2
This blog takes a deep dive into how Postgres CDC to ClickHouse works internally and delves into best practices for data modeling and query tuning. We will cover topics such as data deduplication strategies, handling custom ordering keys, optimizing JOINs, materialized views (MVs) including refreshable MVs, denormalization, and more. You can also apply these learnings to one-time migrations (not CDC) from Postgres, so we expect this to help any Postgres users looking to use ClickHouse for analytics. We published a v1 of this blog late last year; this one will be an advanced version of that blog…Redefining AI-Ready Data for Production
Delivering “AI-ready” data has become a zero-day priority for nearly every enterprise data strategy. But while every team might be pursuing it, very few teams I’ve spoken to have a working definition of what “AI-readiness” actually means. In this article, I’ll present a practical framework for building AI-ready data foundations based on hundreds of my own conversations with data and AI professionals shipping AI to production—and how you can get started with your own…Vector Indices Explained Through the FES Theorem
Vectors, which are high-dimensional embeddings of objects, such as text documents or images, are used in a wide range of modern LLM-based/agentic applications. Vector indices, which quickly find a set of vectors that are similar to each other are becoming a core part of many modern data systems…Today…I will write about the foundations of a particular vector index design called hierarchical navigable small worlds (HNSW) indices. This is the design used by most modern vector indices in practice…Distributed Training Lexicon
Below contains 50 terms often used with Distributed Training, and a few visualizations made with Manim in the hopes to give you a quick reference to some of the terminology you may see online…Google users are less likely to click on links when an AI summary appears in the results
Analysis found that Google users were less likely to click on result links when visiting search pages with an AI summary compared with those without one. For searches that resulted in an AI-generated summary, users very rarely clicked on the sources cited…
The White House's plan for open models & AI research in the U.S.
Today, the White House released its AI Action Plan, the document we’ve been waiting for to understand how the new administration plans to achieve “global dominance in artificial intelligence (AI).” There’s a lot to unpack in this document, which you’ll be hearing a lot about from the entire AI ecosystem. This post covers one narrow piece of the puzzle — its limited comments on open models and AI research investment…
Dynamic Inventory Optimization with Censored Demand
A sequential decision framework with Bayesian learning…Businesses face a crucial question: how much to stock?…This decision must often be made before demand is fully known; that is, under censored demand. If the business overstocks, it observes the full demand, since all customer requests are fulfilled. But if it understocks, it only sees that demand exceeded supply and the actual demand remains unknown, making it a censored observation….This type of problem is often referred to as a Newsvendor Model. In fields such as operations research and applied mathematics, the optimal stocking decision has been studied by framing it as a classic newspaper stocking problem; hence the name…In this article, we explore a Sequential Decision-Making framework for the stocking problem under uncertainty and develop a dynamic optimization algorithm using Bayesian learning…
Postgres CDC to Iceberg: Lessons from Real-World Data Pipelines
Connecting these two systems in real-time is far from trivial. To continuously replicate Postgres changes into Iceberg, you need a reliable CDC (Change Data Capture) pipeline…But after diving into real-world production cases and discussing the technical details with dozens of engineering teams, I realized that streaming data from Postgres CDC to Iceberg is far from a “solved problem.”…In this post, I’ll break down these challenges one by one and share lessons learned from real-world scenarios…Behind the Streams: Three Years Of Live at Netflix. Part 1
What began with an engineering plan to pave the path towards our first Live comedy special, Chris Rock: Selective Outrage, has since led to hundreds of Live events ranging from the biggest comedy shows and NFL Christmas Games to record-breaking boxing fights and becoming the home of WWE…In our series Behind the Streams — where we take you through the technical journey of our biggest bets — we will do a multiple part deep-dive into the architecture of Live and what we learned while building it. Part one begins with the foundation we set for Live, and the critical decisions we made that influenced our approach…The Surprising gRPC Client Bottleneck in Low-Latency Networks — and How to Get Around It
We use gRPC to expose our database API to clients. Therefore, all our load generators and benchmarks are gRPC clients. Recently, we discovered that the fewer cluster nodes we have, the harder it is for the benchmark to load the cluster. Moreover, when we shrink the cluster size, it results in more and more idle resources, while we observe steadily increasing client-side latency. Fortunately, we identified the root cause as a bottleneck on the client side of gRPC. In this post, we describe the issue and the steps to reproduce it using a provided gRPC server/client microbenchmark. Then, we show a recipe to avoid the discovered bottleneck and achieve high throughput and low latency simultaneously…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #608 here.
Cutting Room Floor
That time I wasted weeks hand optimizing assembly because I benchmarked on random data
Randomization Can Reduce Both Bias and Variance: A Case Study in Random Forests
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,400 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian