
Data Science Weekly - Issue 616
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #616
September 11, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Minesweeper thermodynamics
You know how sometimes you start a game of Minesweeper and immediately get stuck? Like maybe there are some cells that you know are mines, but there aren’t any places that are safe to click…In statistical mechanics, the Boltzmann distribution is a law that tells you how likely a physical system is to be in a particular state. It works in the context that your system is in equilibrium with a larger environment that acts as a ‘heat bath’, holding it at a particular temperature 𝑇…I want to apply it to Minesweeper. The idea is that our little corner of the Minesweeper grid is like a physical system within a larger environment; a ‘mine bath’…
30 minutes with a stranger
In this story, we’ll go through 30 minutes of conversation between the people you see here…They are a subset of nearly 1,700 conversations between about 1,500 people as part of a research project called the CANDOR corpus. The goal was to gather a huge amount of data to spur research on how we converse…Building Vector Tiles from scratch
As I add more data to the NYC Chaos Dashboard, a website that maps live urban activity, I have been looking for a more efficient way to render the map. Since I collect all of the data in one process and return the Dashboard as one HTML file, I kept wondering how I could optimize the map’s loading time by pre-processing the data as much as possible in the backend. This is where vector tiles come in…
What’s on your mind
This Week’s Poll:
I recently signed up for one and it's awesome and way less stressful than opening my inbox and seeing 72 million newsletters all vying for my attention. Right now I get 2 newsletters in paper via mail per month and it’s great!
.
Last Week’s Poll:
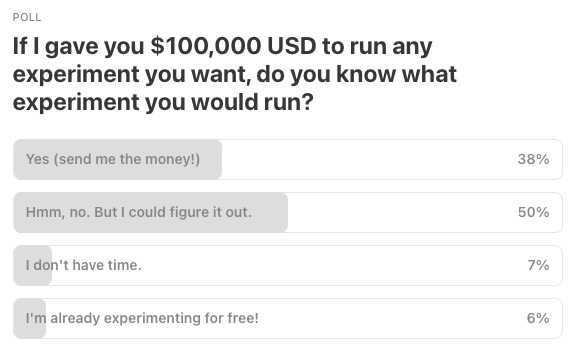
Now we’re super curious about what you all would do!
.
Data Science Articles & Videos
Challenges in Statistics: A Dozen Challenges in Causality and Causal Inference
Our goal in this discussion is to outline research directions and open problems we view as particularly promising for future work. Throughout we emphasize that advancing causal research requires a wide range of contributions, from novel theory and methodological innovations to improved software tools and closer engagement with domain scientists and practitioners…Professionals who perform at the top 10% of their respective organizations [Reddit]
What’s something you do that most people around you don’t?…
The two versions of Parquet
A few days ago, the creators of DuckDB wrote the article: Query Engines: Gatekeepers of the Parquet File Format, which explained how the engines that process Parquet files as SQL tables are blocking the evolution of the format. This is because those engines are not fully supporting the latest specification, and without this support, the rest of the ecosystem has no incentive to adopt it…Transparent, Robust and Ultra-Sparse Trees (TRUST)
It achieves comparable accuracy to state-of-the-art machine learning algorithms - including black box models like Random Forest - while remaining fully interpretable. Scroll down for a short demo of TRUST. Current version solves regression problems (variants like time series only experimentally). Extensions to multiclass classification and beta regression are already under development and I will soon make them available as well…Welcome to the synthetic data tutorial
This self-paced tutorial will introduce you to the generation and evaluation of synthetic data. Synthetic data is generated data that can be used as an alternative to privacy-sensitive data, for example to enhance open science practices. Advantages of open (synthetic) data are numerous: other researchers can re-run analyses with data that is close to the actual data, which allows them to verify the main results. Additionally, open (synthetic) data allows researchers to perform exploratory analyses that may lead to novel hypotheses, and in quite some instances performing such analyses with synthetic data yields rather accurate results…Dataframes in Haskell
The goal of this document is to detail the design of a dataframe library for exploratory data analysis (EDA) in Haskell. In addition to fulfilling the usual functional requirements of a dataframe library, the library must also have many modern features learned from years of development in the space…Bayesian Inference is Just Counting
Conceptual introduction to Bayesian data analysis, focusing on foundations and causal inference. Nothing really about computational details…From Frequencies to Coverage: Rethinking What “Representative” Means
Whether you build an image classifier or want to estimate the average rent in Bologna, you need data. But not just any data, the data should be “representative”: A dog image classifier shouldn’t only be trained on images of dogs in spooky costumes, and the Bologna dataset shouldn’t only contain apartments above restaurants. But what exactly does “representative” mean? Let’s start with a very general definition…Simulating and Visualising the Central Limit Theorem
In this post I want to interrogate and explore the CLT using simulation and visualisation in an attempt to understand how it works in practice, not in theory…
How to Spot (and Fix) 5 Common Performance Bottlenecks in pandas Workflows
Slow data loads, memory-intensive joins, and long-running operations—these are problems every Python practitioner has faced. They waste valuable time and make iterating on your ideas harder than it should be. This post walks through five common pandas bottlenecks, how to recognize them, and some workarounds you can try on CPU with a few tweaks to your code…Why Netflix Struggles To Make Good Movies: A Data Explainer
Why do Netflix films keep falling flat?…What genuinely interests me is finding a plausible explanation for why a $530 billion company consistently falls short in its attempts to make great movies. So today, we'll unpack what drives Netflix's underwhelming film output—and explore what purpose these streaming movies are supposed to serve…
Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
Not too long ago, AWS dropped something new: S3 Vectors. It’s their first attempt at a vector storage solution, letting you store and query vector embeddings for semantic search right inside Amazon S3…instead of “killing” vector databases, I see it fitting into the ecosystem as a complementary piece. In fact, its real future probably lies in working with professional vector databases, not replacing them. In this post, I’ll walk you through why I think that—looking at it from three angles: the tech itself, what it can and can’t do, and what it means for the market…Data Modeling Guide for Real-Time Analytics with ClickHouse:
From S3 Ingestion to Sub-Second Dashboards
This article is for data engineers and practitioners who want to build analytics that deliver sub-second query responses, and who want to unlock ClickHouse’s full potential for real-time analytics demands. By the end, you’ll have a playbook for ClickHouse data modeling plus a working example that ingests NOAA weather data from S3 and visualizes it with a single configuration file…
.
Last Week's Newsletter's 3 Most Clicked Links
What over-engineered tool did you finally replace with something simple?
DSPy 0‑to‑1 Guide: Building Self‑Improving LLM Applications from Scratch
.
* Based on unique clicks.
** Find last week's issue #615 here.
Cutting Room Floor
Against the Uncritical Adoption of 'AI' Technologies in Academia
Patterns, Predictions, and Actions: A story about machine learning [Book]
Untangling Sample and Population Level Estimands in Bayesian Causal Inference
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Hi. I'm the author of "Dataframes in Haskell". I'm curious how the article was discovered.
Thank you so much! This week's newsletter is great...especially the book "Patterns, Predictions and Actions". I just began digging in and I am so excited. I spend time, almost every week, in Duda and Hart's "Pattern Classification and Scene Analysis". I know this book is going to be GREAT!