
Data Science Weekly - Issue 617
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #617
September 18, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Stein’s Paradox in Statistics
The best guess about the future is usually obtained by computing the average of past events. Stein’s paradox defines circumstances in which there are estimators better than the arithmetic average…
Coding assignments in ChatGPT/Cursor era
In the era of SWE-bench and various arenas for LLMs, the question “can LLMs code?” is obsolete. Of course, they can and I personally use ChatGPT and Sonnet4 daily. They are good…Now, the real question is – if the LLMs are so good, why students are struggling with coding assignments for computer vision course every year? Does Chat have any problem with coding the gaussian blur? Are students very honest and not using it at all? Are they using LLMs, but something is wrong?…Those are the questions, which I have tried to answer last semester…A practical overview on probability distributions
Aim of this paper is a general definition of probability, of its main mathematical features and the features it presents under particular circumstances. The behavior of probability is linked to the features of the phenomenon we would predict. This link can be defined probability distribution. Given the characteristics of phenomena (that we can also define variables), there are defined probability distribution…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
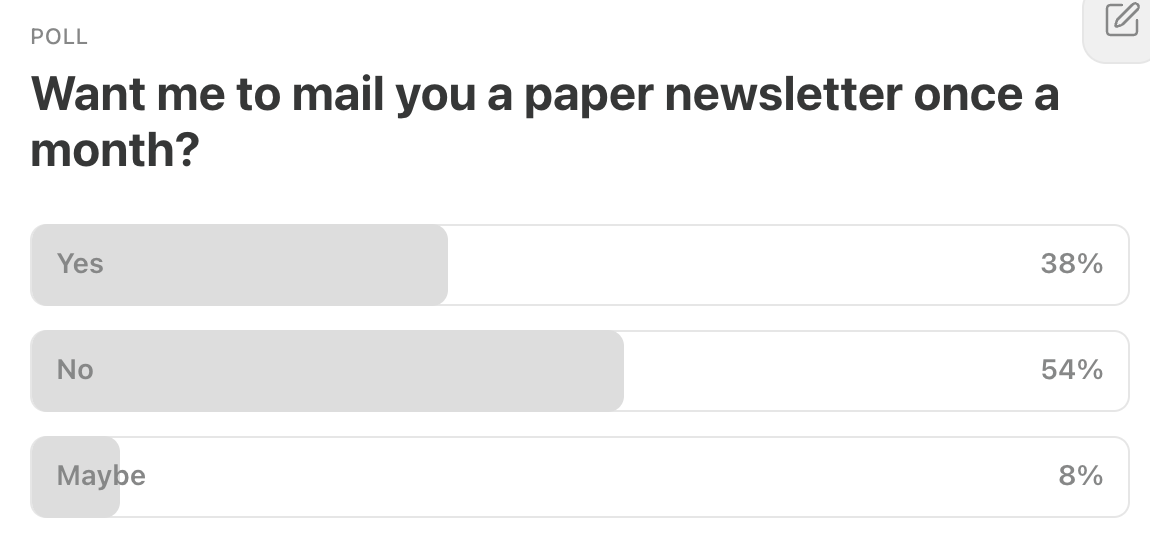
.
Data Science Articles & Videos
If all the world were a monorepo
The R ecosystem and the case for extreme empathy in software maintenance…As a software engineer raised on a traditional diet of C, Java, and Lisp, I’ve found myself downright baffled by R. I’m no stranger to mastering new programming languages, but learning R was something else: it felt like studying Finnish after a lifetime of speaking Romance languages. I’m not alone in this experience…In the years since, my discomfort has given away to fascination. I’ve come to respect R’s bold choices, its clarity of focus, and the R community’s continued confidence to ‘do their own thing’…Which papers HAVEN'T stood the test of time? [Reddit]
As in title! Papers that were released to lots of fanfare but haven't stayed in the zeitgeist also apply. Less so "didn't stand the test of time" but I'm thinking of KANs. Having said that, it could also be that I don't work in that area, so I don't see it and followup works. I might be totally off the mark here so feel free to say otherwise…
Inside Modal Notebooks: How we built a cloud GPU notebook that boots in seconds
We recently launched Modal Notebooks, a new cloud Jupyter notebook that boots GPUs and arbitrary custom images in seconds, all with real-time collaboration. I want to share some of the engineering that made this experience possible. This post isn’t about features, but about the systems work behind running interactive, high-performance GPU workloads in the cloud while still feeling instantaneous…On the (Mis)Use of Machine Learning With Panel Data
We provide the first systematic assessment of data leakage issues in the use of machine learning on panel data. Our organising framework clarifies why neglecting the cross-sectional and longitudinal structure of these data leads to hard-to-detect data leakage, inflated out-of-sample performance, and an inadvertent overestimation of the real-world usefulness and applicability of machine learning models…SQL performance improvements: finding the right queries to fix (part 1)
A few weeks ago, we massively improved the performance of the dashboard & website by optimizing some of our SQL queries. In this post, we'll share how we identified the queries that needed work. In the next post, we'll explore how we fixed each of them. We'll cover the basics and gradually work our way up to the more advanced/complex ways of identifying slow queries…How We Built the First AI-Generated Genomes
Here we detail some of the technical innovations that enabled us to generate viable bacteriophage genomes with substantial evolutionary novelty. Our approach required developing a comprehensive computational and experimental design framework, including a custom gene annotation pipeline for overlapping reading frames, systematic fine-tuning and prompt engineering strategies for sampling from genome language models, and new screening protocols for synthetic phage genomes…Trick for Backpropagation of Linear Transformations
Linear transformations such as sums, matrix products, dot products, Hadamard products, and many more can often be represented using an einsum (short for Einstein summation). This post explains a simple trick to backpropagate through any einsum, regardless of what operations it represents…Attention sinks from the graph perspective
Attention sinks have recently come back to the forefront of architecture discussion, especially due to their appearance in gpt-oss (although in a different form than the effect we're discussing today). As a mechanism, attention sinks are easy to describe: when trained, decoder-only transformer models tend to allocate a disproportionate amount of attention to the first few tokens, and especially to the first…In this blogpost, we will argue that there is a significant bias in decoder-only transformers that may be to blame, at least partially, for this phenomenon. Moreover, this will also allow us to introduce a series of blogposts focused on analyzing transformers from the lens of message passing on graphs…We’re tickled pink to announce the release of ggplot2 4.0.0. ggplot2 is a system for declaratively creating graphics, based on The Grammar of Graphics. You provide the data, tell ggplot2 how to map variables to aesthetics, what graphical primitives to use, and it takes care of the details…
Data Skills for Reproducible Research
This book provides an overview of skills needed for reproducible and open research using the statistical programming language R and tidyverse packages. It covers reproducible workflows, data visualisation, data tidying and wrangling, archiving, iteration and functions, probability and data simulations…Complete Guide to Applying Functions to Each Row in R Matrices and Data Frames
Learn how to use the apply() function in R to efficiently perform row-wise operations on matrices and data frames. This comprehensive guide covers syntax, practical examples, troubleshooting tips, and best practices for R programmers looking to streamline their data analysis workflows…
I am responsible for arguably the biggest run project using AI in production in my country - AMA [Reddit]
I have been doing AI for quite a while and where most projects don't go beyond pilot or PoC, all mine have ended up in production (systems)…Some stats:More than €10M total budget, reduced to actuals of under 5%
50 billion tokens spent
Roughly up to €50k on LLM (prompt) spent alone
First working version developed in 2 weeks, followed by 6 months of (quality) improvements
Conversion done in 1 weekend
Fire away with questions…
Easily clean up messy databases with fuzzy matching in R
One of the biggest challenges working with text data is the many different ways that people can enter the exact same information. A human knows that “St. Lucie, Florida,” “Saint Lucie, FL,” and “St Lucy, Florida” are probably all the same place, but a computer doesn’t. “Fuzzy” matching pulls similarities between the letters in words and phrases to help group them together…
.
Last Week's Newsletter's 3 Most Clicked Links
Challenges in Statistics: A Dozen Challenges in Causality and Causal Inference
Generating and evaluating synthetic data in R - Welcome to the synthetic data tutorial!
.
* Based on unique clicks.
** Find last week's issue #616 here.
Cutting Room Floor
Reduction of methane emissions through improved landfill management
Evaluation of machine learning-assisted directed evolution across diverse combinatorial landscapes
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian