
Data Science Weekly - Issue 618
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #618
September 25, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Building GenAI Systems That Make Business Decisions with Thomas Wiecki
In this episode, we look at two real-world systems that go beyond prompting: one used by Colgate to simulate consumer reactions to new product ideas (like mango-flavored toothpaste), and another agent that automates complex modeling workflows to guide media spend decisions. We talk with Thomas Wiecki (co-author to PyMC) about what it takes to build GenAI systems that hold up in production… and what these examples tell us about where generation ends and real structure begins…
R-Ladies YouTube Video Feed
The purpose of this dashboard is to provide a running feed of R-Ladies videos posted to YouTube. It is refreshed every 24 hours…The wonderful Math that powers Disney’s Animation
I used to think that the link between math and art has always been somewhat tenuous until I recently discovered the kinds of math the animation artists at Disney Studios have been working on…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
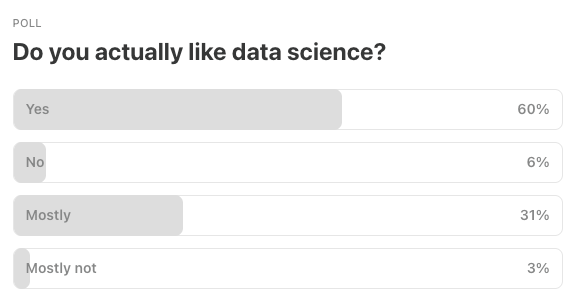
.
Data Science Articles & Videos
Introducing SedonaDB: A single-node analytical database engine with geospatial as a first-class citizen
SedonaDB is the first open-source, single-node analytical database engine that treats spatial data as a first-class citizen. It is developed as a subproject of Apache Sedona. Apache Sedona powers large-scale geospatial processing on distributed engines like Spark (SedonaSpark), Flink (SedonaFlink), and Snowflake (SedonaSnow). SedonaDB extends the Sedona ecosystem with a single-node engine optimized for small-to-medium data analytics, delivering the simplicity and speed that distributed systems often cannot…Is senior ML engineering just API calls now? [Reddit Discussion]
I’m a Senior ML engineer with around 9 years of experience. I work at a large government institution, implementing (integrating?) AI for cybersecurity, and I’m currently in the process of building a new team…It seems like the industry has shifted from building models to API calls and prompt engineering. I miss the kind of work I did in my earlier roles, building models from scratch, fine-tuning, experimenting… So my question is: is this just what senior ML roles eventually turn into? Has the job really shifted from “building ML” to “plugging in ML”? Curious if others are experiencing the same thing. I have been experiencing this since the generative AI boom where suddenly everything was solvable….
How to interpret “confidence intervals” in observational studies
This question complements the one in the thread Random sampling versus random allocation/randomization- implications for p-value interpretation. Given that observational studies involve neither random sampling nor random allocation, why are they riddled with “95% confidence intervals”?plumber2 0.1.0
I’m super excited to announce the release of the plumber2 package on CRAN. plumber2 is a package for creating webservers in R based on either an annotation-based or programmatic workflow. It is the successor to the plumber package who has empowered the R community for 10 years and allowed them to share their R based functionalities with their organizations and the world…Slidecrafting - Making beautiful slides with reveal.js and Quarto
This book is about what I like to call slidecrafting; The art of putting together slides that are functional and aesthetically pleasing. I will be using quarto presentations throughout the whole book. Some of the advice will transcend Quarto presentations and apply to all kinds of slide technologies, but the book is written with Quarto in mind. There will thus inherently be some overlap with quarto documentation…Why are embeddings so cheap? (or a lesson in profiling and FLOPS per dollar)
Embeddings are a fundamental component of every modern retrieval augmented generation (RAG) system. State-of-the-art (SOTA) embeddings are provided by companies such as OpenAI or Google at prices up to two orders of magnitude lower on a per-token basis than prices for generative models such as GPT or Gemini. In this analysis, we show what computations are required to produce an embedding and how, based on these computations, we can derive the true dollar cost of processing a token…My First Time Vibe-Conf’ing
posit::conf(2025) was the first conference I’ve been to where I could just “vibe” Here’s my personal recap of how that went…I attended with no talks submitted, no expectations, just good vibes. I don’t know if I’ll submit next year (I have a backlog of ideas) or just vibe again. For now, let me dive into what this experience was like…dspy-profiles
A companion tool for the DSPy framework to manage configuration profiles, inspired by the AWS CLI. dspy-profiles allows you to define, switch between, and manage different DSPy configurations for various environments (e.g., development, staging, production) without cluttering your code…AI-Powered Decision Making Under Uncertainty
In this workshop, you’ll learn how to develop Bayesian intuition and build powerful probabilistic models using PyMC…Making decisions under uncertainty is hard — especially when your data is limited, your outcomes are rare, or your assumptions are hidden. 😭. You’ll see how modern Bayesian modeling can:
Estimate probabilities with informative priors.
Compare alternatives probabilistically with Bayesian A/B testing.
Share strength across groups using hierarchical models.
Evaluate and anticipate rare events using posterior predictive distributions…
On Impactful AI Research
Grad students often reach out to talk about structuring their research, e.g. how do I do research that makes a difference in the current, rather crowded AI space?…This post distills thoughts on impact I’ve been sharing with folks who ask. Impact takes many forms, and I will focus only on making research impact in AI via open-source work through artifacts like models, systems, frameworks, or benchmarks…nvmath-python: NVIDIA Math Libraries for the Python Ecosystem
nvmath-python brings the power of the NVIDIA math libraries to the Python ecosystem. The package aims to provide intuitive pythonic APIs that provide users full access to all the features offered by NVIDIA’s libraries in a variety of execution spaces. nvmath-python works seamlessly with existing Python array/tensor frameworks and focuses on providing functionality that is missing from those frameworks…
What’s the right thing to say to salary expectations question? [Reddit Dicussion]
I have come across usually two types of scenarios here and I am not sure what’s the best way to deal.I ask for a range and they give you range. Should you just say you’re okay with the range? But what if I make 80K now and their range is 90-120. In this case I don’t wanna move at 90K. What should you say?
They just don’t give you any range and keep pressing to give them a number. In this case I feel like there’s chances of getting low balled later.
I have a couple of recruiter rounds coming up. Could really use your help…
Modern Statistics with R
The aim of Modern Statistics with R is to introduce you to key parts of the modern statistical toolkit. It teaches you:Data wrangling - importing, formatting, reshaping, merging, and filtering data in R.
Exploratory data analysis - using visualisations and multivariate techniques to explore datasets.
Statistical inference - modern methods for testing hypotheses and computing confidence intervals.
Predictive modelling - regression models and machine learning methods for prediction, classification, and forecasting.
Simulation - using simulation techniques for sample size computations and evaluations of statistical methods.
Ethics in statistics - ethical issues and good statistical practice.
R programming - writing code that is fast, readable, and (hopefully!) free from bugs…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #617 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,500 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian