
Data Science Weekly - Issue 625
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #625
November 13, 2025
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Python is not a great language for data science. Part 1: The experience
It may be a good language for data science, but it’s not a great one…I think people way over-index Python as the language for data science. It has limitations that I think are quite noteworthy. There are many data-science tasks I’d much rather do in R than in Python…I believe the reason Python is so widely used in data science is a historical accident, plus it being sort-of Ok at most things, rather than an expression of its inherent suitability for data-science work…
The Log: What every software engineer should know about real-time data’s unifying abstraction
You can’t fully understand databases, NoSQL stores, key value stores, replication, paxos, hadoop, version control, or almost any software system without understanding logs; and yet, most software engineers are not familiar with them. I’d like to change that. In this post, I’ll walk you through everything you need to know about logs, including what is log and how to use logs for data integration, real time processing, and system building…Using LEGO® Brick Data to Teach SQL and Relational Database Concepts
As a guiding example, I introduce an example group project assignment designed to provide students hands-on experience with database management and SQL queries. I also discuss tips, suggestions, and lessons learned from using the data for group projects over the past five years. While LEGO® bricks have been widely used in educational settings, including college and computer classrooms, this is the first work to discuss the use of LEGO® data in a college database course…
.
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
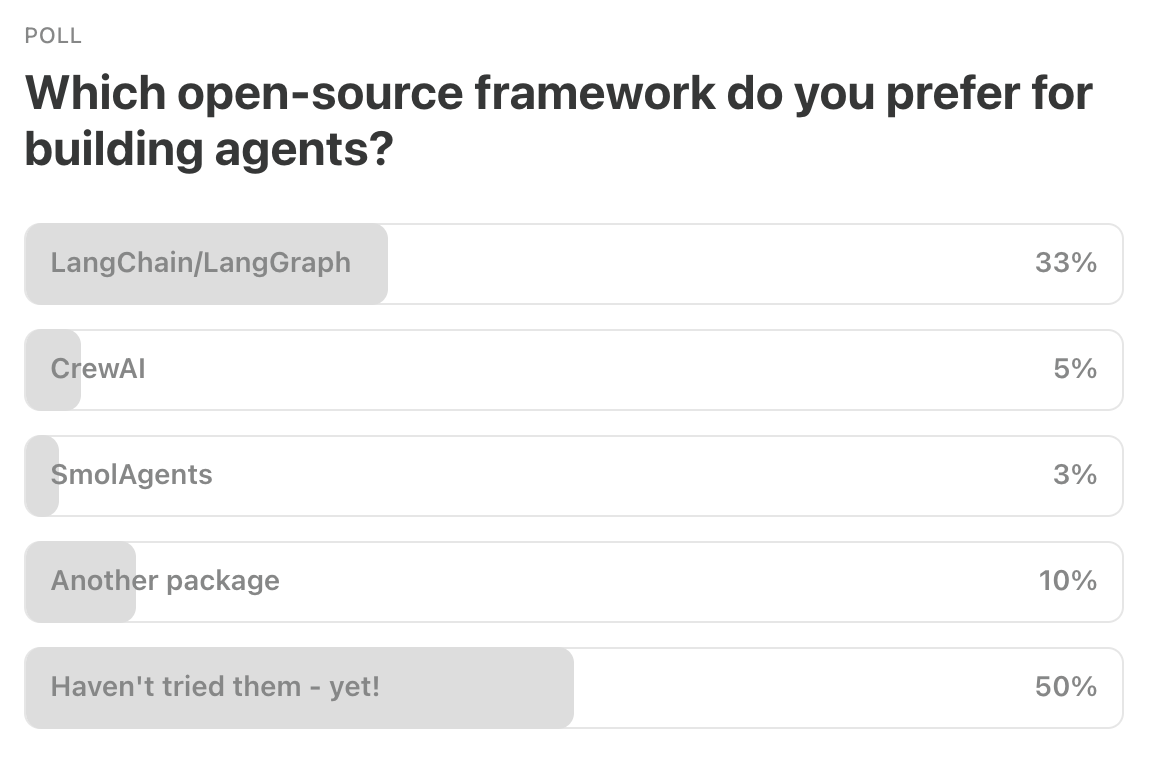
.
Data Science Articles & Videos
Learnings after 4 years working with +50 companies on data engineering projects
I’ve probably talked to more than 100 companies and actively helped +50, ranging from those with just a few employees and Gigabytes of data to top companies in the world with Terabytes…Some practical learnings, in no particular order:..I’m a co-founder hiring ML engineers and I’m confused about what candidates think our job requires…I run a tech company and I talk to ML candidates every single week. There’s this huge disconnect that’s driving me crazy and I need to understand if I’m the problem or if ML education is broken.
What candidates tell me they know:
Transformer architectures, attention mechanisms, backprop derivations
Papers they’ve implemented (diffusion models, GANs, latest LLM techniques)
Kaggle competitions, theoretical deep learning, gradient descent from scratch
What we need them to do:
Deploy a model behind an API that doesn’t fall over
Write a data pipeline that processes user data reliably
Debug why the model is slow/expensive in production
Build evals to know if the model is actually working
Integrate ML into a real product that non-technical users touch
I’ll interview someone who can explain LoRA fine-tuning in detail but has never deployed anything beyond a Jupyter notebook. Or they can derive loss functions but don’t know basic SQL…
When to use gamma GLMs?
Whenever I Google something like “practical uses of gamma GLM”, I come up with advice to use it for waiting times between Poisson events. OK. But that seems restrictive and can’t be its only use. Naively, it seems like the gamma GLM is a relatively assumption-light means of modeling non-negative data, given gamma’s flexibility. Of course you need to check Q-Q plots and residual plots like any model. But are there any serious drawbacks that I am missing? Beyond communication to people who “just run OLS”?…State of AI: November 2025 newsletter
Welcome to the latest issue of the State of AI, an editorialized newsletter formerly known as Guide to AI that covers the key developments in AI policy, research, industry, and start-ups over the last month…AWS - Beyond vibes: How to properly select the right LLM for the right task
Choosing the right large language model (LLM) for your use case is becoming both increasingly challenging and essential. Many teams rely on one-time (ad hoc) evaluations based on limited samples from trending models, essentially judging quality on “vibes” alone…In this post, we discuss an approach that can guide you to build comprehensive and empirically driven evaluations that can help you make better decisions when selecting the right model for your task…Heartbeats in Distributed Systems
In distributed systems, one of the fundamental challenges is knowing whether a node or service is alive and functioning properly. Unlike monolithic applications, where everything runs in a single process, distributed systems span multiple machines, networks, and data centers. This becomes even glaring when the nodes are geographically separated. This is where heartbeat mechanisms come into play…Imagine a cluster of servers working together to process millions of requests per day. If one server silently crashes, how quickly can the system detect this failure and react? How do we distinguish between a truly dead server and one that is just temporarily slow due to network congestion? These questions form the core of why heartbeat mechanisms matter…When plotting, LLMs see what they expect to see
Data science agents need to accurately read plots even when the content contradicts their expectations. Our testing shows today’s LLMs still struggle here…posit::conf(2025) Videos
Welcome to the official playlist for posit::conf(2025)! Dive into the latest innovations, cutting-edge techniques, and inspiring insights from the premier open-source data science conference. This year, we celebrated the power of the R and Python communities, with a special focus on the next generation of tools and AI integration…How to Make High-Quality PDFs with Quarto and Typst
In the last couple years, we’ve moved to Typst almost exclusively for making PDFs. Of the two promises that Typst makes (powerful and easy to learn), we agree with the first. The second, however, a bit less so. The Typst website has great documentation, but it mostly covers how to write directly in Typst, rather than working in Quarto and rendering with Typst. People often ask me how we make reports with Typst, but I don’t have anywhere to point them to. So, in conjunction with consultant Joseph Barbier (who has become a true expert in creating custom Typst templates), here is an extended tutorial on making high-quality PDFs using Quarto and Typst. We’ll recreate most elements of the childhood immunization reports we recently made for the Johns Hopkins University International Vaccine Access Center…
Colocating Input Partitions with Kafka Streams When Consuming Multiple Topics: Sub-Topology Matters!
Understanding how sub-topology design influences partition co-location…This article outlines the behavior of Kafka Streams when consuming from multiple topics (specifically two) with identical partition counts and similar key strategies. It details our expectations regarding partition assignments, the unexpected distribution behavior we encountered in production, and the architectural changes we implemented to enforce partition colocation — critical for achieving caching efficiency in our use case…Learning R with humorous side projects
What should you name a new dinosaur discovery, according to neural networks? Which season of The Golden Girls should you watch when playing a drinking game? How can you build a LEGO set for the lowest price? R is constantly evolving, so as users, we’re constantly learning…In this talk, I’ll share my experiences with side projects for learning state-of-the-art data science tools and growing as an R user, including how one project helped me land my dream job…
DON’T BE ME !!!!!!! [Reddit]
I just wrapped up a BI project on a staff aug basis with datatobiz where I spent weeks perfecting data models, custom DAX, and a BI dashboard. Looked beautiful. Ran smooth. Except…the client didn’t use half of it. Turns out, they only needed one view, a daily sales performance summary that their regional heads could check from mobile…Anyone else ever gone too deep when the client just wanted a one-page view?…A Visual Introduction to Dimensionality Reduction with Isomap
In this article, I’ll be exploring Isomap, a classic non-linear dimensionality reduction technique that seeks to create a low dimensional embedding of data that preserves its local similarity structure. Isomap builds upon the manifold hypothesis, forming a graph that captures the local structure of data,and projecting points in a way that preserves this structure. This is a pattern that is central to many modern dimensionality reduction techniques like t-SNE and UMAP.The Isomap algorithm has the following high level steps:
First, you construct a graph between points that captures the local structure in the data.
Next, you measure the “geodesic” distances between all pairs of points in this graph. These distances approximate the true manifold distances between points.
Then you apply multi-dimensional scaling to project the high dimensional data into a lower dimensional embedding that preserves the distances from the graph…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #624 here.
Cutting Room Floor
Rethinking Data Discovery for Libraries and Digital Humanities
Bayesian Influence Functions for Hessian-Free Data Attribution
PyOctoMap - Python bindings for the efficient C++ OctoMap library
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Fantastic curated content! This weekly roundup is an excellent resource for staying on top of the latest Data Science, AI, and Machine Learning developments. Love the diverse mix of practical insights and emerging trends. Keep up the amazing work! 🚀