
Data Science Weekly - Issue 632
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #632
January 01, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
R Code Optimization I: Foundations and Principles
This is the first post of a small series focused on code optimization…Here, I draw from my experience developing scientific software in both academia and industry to share practical techniques and tools that help streamline R workflows without sacrificing clarity.This post lays down some of the whats and whys of code optimization.
The second post focuses on code design and readability.
The third post goes deep into vectorization, parallelization, and memory management.
The final post covers profiling, benchmarking, and the optimization workflow
Let’s dig in!..
You will be OK
Wrote this for young people (on LessWrong) worried about AI…I thought I would try to write down why I believe most folks who read and write here (and are generally smart, caring, and knowledgable) will be OK…Accurately computing running variance
The most direct way of computing sample variance or standard deviation can have severe numerical problems…If the x‘s are large and the differences between them small, direct evaluation of the equation above would require computing a small number as the difference of two large numbers, a red flag for numerical computing. The loss of precision can be so bad that the expression above evaluates to a negative number even though variance is always positive…See Comparing three methods of computing standard deviation for examples of just how bad the above formula can be…
What’s on your mind
This Week’s Poll:
.
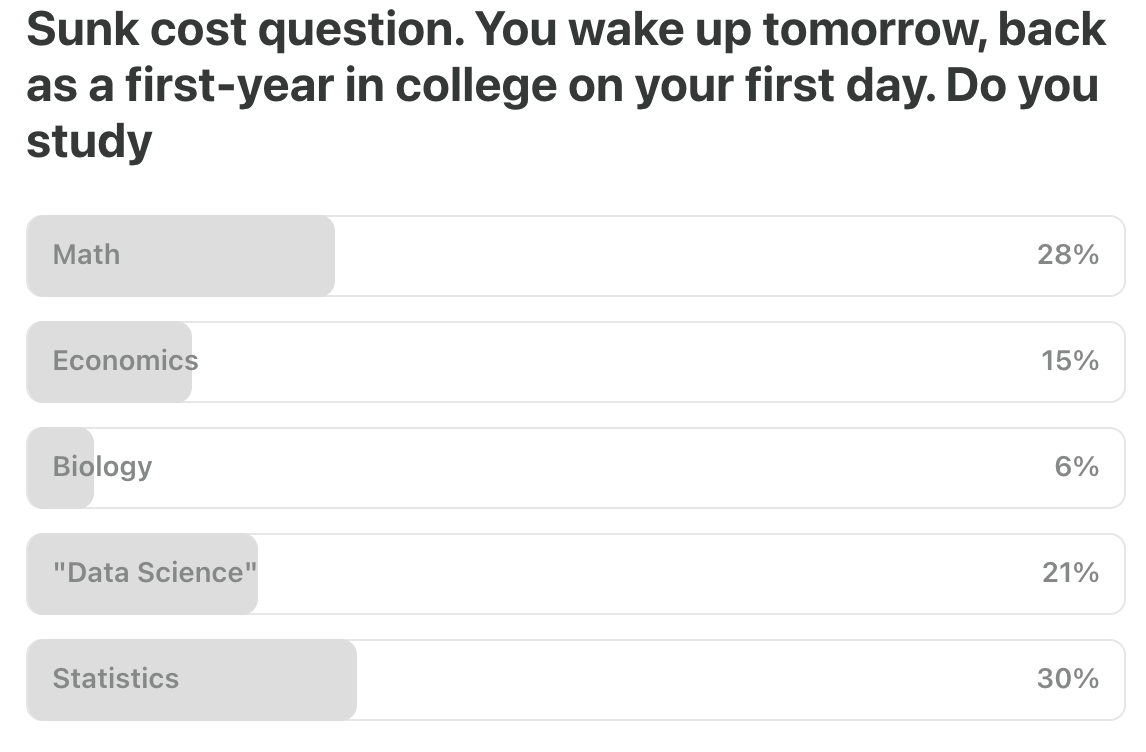
Last Week’s Poll:
.
Featured Book
PROBABLY OVERTHINKING IT
Use Data to Answer Questions and Make Better Decisions
By Allen B. Downey, author of Think Python, Think Bayes, and Think Stats

Now in Paperback!
Think more clearly about data, avoid common statistical pitfalls, and make better decisions in an uncertain world.
Allen speaking about the book: “Probably Overthinking It” Google Talk
“It demands more intellectual engagement than a typical pop science book, drawing readers in with its broad scope of topics and colorful storytelling.”
Book Review by “Implicit Assumptions: “Probably Overthinking It” Book Review
Available from Bookshop.org and Amazon (affiliate links).
.
* Want to be featured in the newsletter? Email us for details --> team@datascienceweekly.org
Data Science Articles & Videos
ML System Design Case Studies Repository
This repository contains a curated collection of 300+ case studies from over 80 companies, detailing practical applications and insights into machine learning (ML) system design. The contents are organized to help you easily find relevant case studies based on industry or specific ML use cases…How much of your (Data) job is actually “selling” your work? [Reddit]
What % of your role is convincing stakeholders to act on your recommendations? Do you like that part, and how did you learn to do it well? Or are you in an environment where good analysis & models naturally leads to implementation?..
Best Data Visualization Projects of 2025
Another year. It passed extremely fast and yet, painfully slow. Despite developing tech that some think might take over our day-to-day work, data things got made by people this year. These are my (Nathan Yau’s) favorites…Python Numbers Every Programmer Should Know
There are numbers every Python programmer should know. For example, how fast or slow is it to add an item to a list in Python? What about opening a file? Is that less than a millisecond? Is there something that makes that slower than you might have guessed? If you have a performance sensitive algorithm, which data structure should you use? How much memory does a floating point number use? What about a single character or the empty string? How fast is FastAPI compared to Django? I wanted to take a moment and write down performance numbers specifically focused on Python developers. Below you will find an extensive table of such values…Old-School Interpretability for LLMs (SHAP Isn’t Dead)
Mechanistic interpretability has taken most of the spotlight when it comes to the interpretation of LLMs. Unfortunately, except for some initial sparks, mechanistic interpretability hasn’t delivered. Especially not for users of large language models. But what about the good old methods of interpreting machine learning models, like Shapley values and other methods that explain the outcome by attributing it to the inputs? Explaining LLMs with such tools is a bit more complex than explaining, say, a random forest regressor on the California housing data, but it’s feasible. In this post, I motivate how attribution methods for LLMs work…For people who have worked as BOTH Data Scientist and Data Engineer: which path did you choose long-term, and why? [Reddit]
I’m trying to decide between Data Science and Data Engineering, but most advice I find online feels outdated or overly theoretical. With the data science market becoming crowded, companies focusing more on production ML rather than notebooks, increasing emphasis on data infrastructure, reliability, and cost, and AI tools rapidly changing how analysis and modeling are done, I’m struggling to understand what these roles really look like day to day. What I can’t get from blogs or job postings is real, current, hands-on experience, so I’d love to hear from people who are currently working (or have recently worked) in either role: how has your job actually changed over the last 1–2 years…Artificial Intelligence for Microbiology and Microbiome Research
This review provides a comprehensive overview of AI-driven approaches tailored for microbiology and microbiome studies, emphasizing both technical advancements and biological insights. We begin with an introduction to foundational AI techniques, including primary machine learning paradigms and various deep learning architectures, and offer guidance on choosing between traditional machine learning and sophisticated deep learning methods based on specific research goals. The primary section on application scenarios spans diverse research areas, from taxonomic profiling, functional annotation & prediction, microbe-X interactions, microbial ecology, metabolic modeling, precision nutrition, clinical microbiology, to prevention & therapeutics. Finally, we discuss challenges in this field and highlight some recent breakthroughs…Rodney Brooks’s Predictions Scorecard, 2026 January 01
This is my eighth annual update on how my dated predictions from January 1st, 2018 concerning (1) self driving cars, (2) robotics, AI , and machine learning, and (3) human space travel, have held up. I promised then to review them at the start of the year every year until 2050 (right after my 95th birthday), thirty two years in total. The idea was to hold myself accountable for those predictions. How right or wrong was I?…What skills did you learn on the job this past year? [Reddit]
What skills did you actually learn on the job this past year? Not from self-study or online courses, but through live hands-on training or genuinely challenging assignments…
No Vibes Allowed: Solving Hard Problems in Complex Codebases
I am pretty measured when it comes to interfacing with the AI hype machine. But we’ve stumbled into workflows that leave me with considerable optimism for what’s possible. We’ve gotten Claude code to handle 300k LOC Rust codebases, ship a week’s worth of work in a day, and maintain code quality that passes expert review. We use a family of techniques I call “frequent intentional compaction “ - deliberately structuring how you feed context to the AI throughout the development process…In this talk, I’ll share what we’ve learned since first sharing these techniques back in August, and some educated predictions on what’s coming in the next 6-12 months for software engineers…The basics of the InnoDB undo logging and history system
InnoDB implements multi-version concurrency control (MVCC), meaning that different users will see different versions of the data they are interacting with (sometimes called snapshots, which is a bit of a misleading term). This is done in order to allow users to see a consistent view of the system without expensive and performance-constraining locking which would limit concurrency…Undo logging and InnoDB’s “history” system are the mechanisms that underly its implementation of MVCC, but the way this works is generally very poorly understood…
There has to be a better way to explain Bayes’ theorem rather than the “librarian or farmer” question [Reddit]
The usual way it’s introduced is by introducing a character with a trait that is stereotypical to a group of people (eg nerdy and meek). Then the question is asked, is the character from that group of people (eg librarians) or from a much larger group of people (eg farmers). It’s supposed to catch people who answer librarians rather than farmers because they “fail” to consider that there are vastly more farmers than librarians…The Raven Paradox
Suppose you are not sure whether all ravens are black. If you see a white raven, that clearly refutes the hypothesis. And if you see a black raven, that supports the hypothesis in the sense that it increases our confidence, maybe slightly. But what if you see a red apple – does that make the hypothesis any more or less likely?…This question is the core of the Raven paradox, a problem in the philosophy of science posed by Carl Gustav Hempel in the 1940s…It highlights a counterintuitive aspect of how we evaluate evidence and confirm hypotheses…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #631 here.
Cutting Room Floor
When Did “Rock” Become “Classic Rock”? A Statistical Analysis
Mass Spectrometry Proteomics: A Key to Faster Drug Discovery
survivalSL: an R Package for Predicting Survival by a Super Learner
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Thanks for sharing this issue! There’s a ton of valuable content here — from R code optimization and Python performance tips to AI applications in microbiology and ML system design. I especially appreciate the focus on practical workflows and reproducibility, which is often overlooked in newsletters.
For anyone looking to deepen their skills further or explore structured courses related to data science, AI, and ML, this resource can be really useful: https://www.icertglobal.com/
Looking forward to seeing more curated insights like these in future issues!
Great curation this week, especially the piece on traditional interpretability methods for LLMs versus mechanistic approaches. The tension between production ML and notebook-heavy data science really captured whats happening in the field right now. I transitioned from pure data science to more engineering-heavy roles last year and that Reddit thread about DE vs DS resonated, the practical infrastructure work feels more impactful than endless model tweaking. Your newsletter consistently surfaces the signal I actually need rather then just AI hype cycles.