
Data Science Weekly - Issue 633
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #633
January 08, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
How Much Does Education Improve Intelligence? A Meta-Analysis
Intelligence test scores and educational duration are positively correlated. This correlation could be interpreted in two ways: Students with greater propensity for intelligence go on to complete more education, or a longer education increases intelligence. We meta-analyzed three categories of quasiexperimental studies of educational effects on intelligence: those estimating education-intelligence associations after controlling for earlier intelligence, those using compulsory schooling policy changes as instrumental variables, and those using regression-discontinuity designs on school-entry age cutoffs. Across 142 effect sizes from 42 data sets involving over 600,000 participants, we found consistent evidence for beneficial effects of education on cognitive abilities of approximately 1 to 5 IQ points for an additional year of education…
Papers in 100 Lines of Code
Implementation of ML papers in 100 lines of code.Inside NVIDIA GPUs: Anatomy of high-performance matmul kernels
From GPU architecture and PTX/SASS to warp-tiling and deep asynchronous tensor core pipelines…In this post, I will gradually introduce all of the core hardware concepts and programming techniques that underpin state-of-the-art (SOTA) NVIDIA GPU matrix-multiplication (matmul) kernels…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
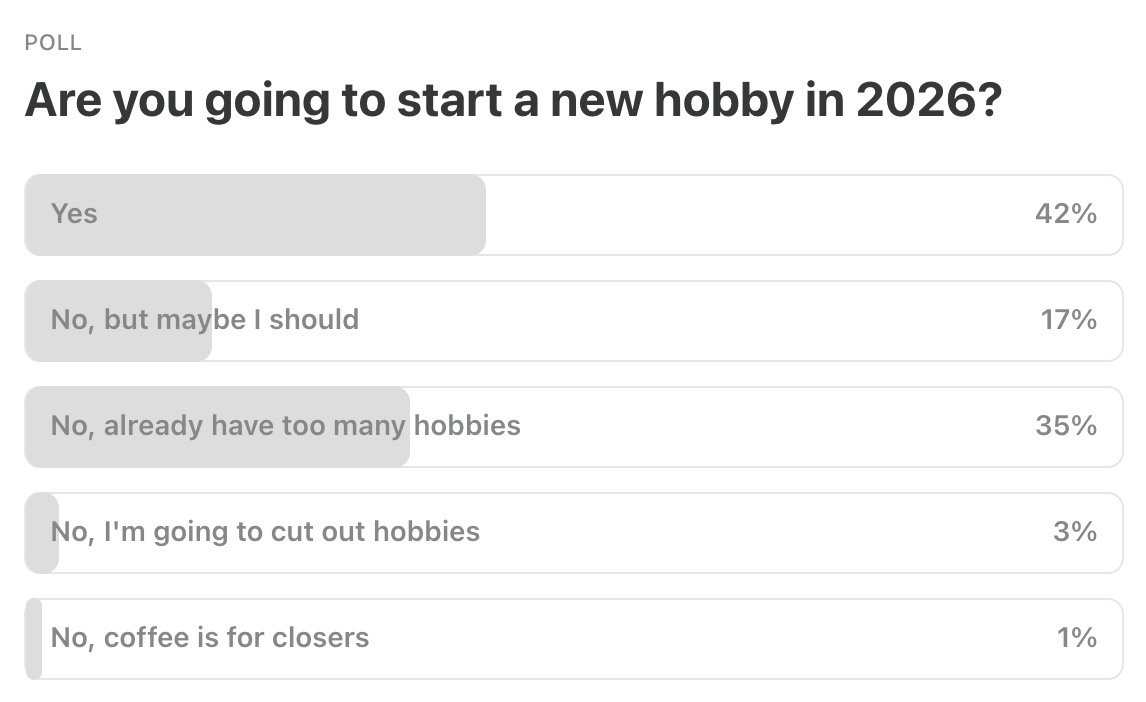
.
Data Science Articles & Videos
How do language models solve Bayesian network inference?
This post explores: how do current frontier LLMs handle probabilistic inference on a Bayesian network? I’ll walk through the Variable Elimination algorithm since it is one of the easiest to understand and implement, solve an example by hand with it, and then compare how seven reasoning LLMs approach the same query, analyzing not just whether they get the right answer, but how they reason through the problem…How different are Data Scientists vs Senior Data Scientists technical interviews? [Reddit]
I am preparing for a technical interview for a Senior DS role and wanted to hear from those that have gone through the process, is it much different? Do you prepare in the same way? Leet code and general ML and experimentation knowledge?
Compiler Engineering In Practice - Part 2: Why is a compiler?
Ask most people what a compiler does, and you’ll get an answer about translating high-level code into machine instructions. Ask them why a compiler exists, and you’ll likely hear something about performance—getting code to run fast. This answer, while not entirely wrong, misses the forest for the trees. The real purpose of a compiler is far more interesting, and understanding it changes how you think about compiler design and language evolution…MIT 16.485 - Visual Navigation for Autonomous Vehicles
MIT’s Visual Navigation for Autonomous Vehicles course covers the full perception-to-control stack, not just isolated algorithms…What it focuses on:
• 2D and 3D vision for navigation
• Visual and visual-inertial odometry for state estimation
• Place recognition and SLAM for localization and mapping
• Trajectory optimization for motion planning
• Learning-based perception in geometric settings…Claude turns my old blog posts into interactive Marimo lessons now
I still don’t count myself as an LLM maximalist ... but ... this exercise did make me rethink the utility of Claude Opus…Sensitivity of urban structure-temperature relationships to grid parameterization
Grid-based aggregations are widely used in geographic analyses to summarize spatial data, yet the sensitivity of these methods to grid size and orientation remains poorly understood, a challenge known as the Modifiable Areal Unit Problem…Here, we examined how changes in grid cell size and orientation affect the representation of urban landscape structure and surface temperature in New York City using summer 2008 data. We applied the Structure of Urban Landscapes (STURLA) classification to Landsat 7 thermal data (60 m resolution), testing grid resolutions from 10 m to 10,000 m and orientations from 0° to 180°…Specific gridsearch
I am copying a pattern from Simon Willison by also having Claude Code write me some notebooks on occasion about algorithm-peformance things that I’m curious about...The topic of todays exercise is GridSearchCV from scikit-learn and ways it could be so much faster if you designed it to work for specific use-cases. Under the hood it uses joblib/pickle to serialise scikit-learn pipelines and this comes at a cost. I had Claude write me a notebook to compare a few different approaches for linear models, specifically…A Hitchhiker’s Guide to Information Theoretical Measures in Psychology
In psychology, as in other sciences, information theory can be used as a tool to complement more standard regression-based methods of data analysis. It is important to see the potential of information-theoretical measures as statistical tools without implying a connection to their origins in communication theory and engineering. The use of these measures may provide us with additional insights due to their sensitivity to non-linear relationships, their flexibility to the mixing of data types, and their more straightforward generalization towards investigating higher-order interactions. We briefly reintroduce information theory and compare several measures such as mutual information and co-information with correlation and regression-based methods for the investigation of variable dependence…Reduce Outlier Effects Using Robust Regression
You can reduce outlier effects in linear regression models by using robust linear regression. This page defines robust regression, shows how to use it to fit a linear model, and compares the results to a standard fit…
Extracting Books from Production Language Models
We extract thousands of words of memorized books from production language models…Our work highlights that, even with model- and system-level safeguards, extraction of (in-copyright) training data remains a risk for production LLMs…Verification-Driven Development (VDD) via Iterative Adversarial Refinement
Verification-Driven Development (VDD) is a high-integrity software engineering framework designed to eliminate “code slop” and logic gaps through a generative adversarial loop. Unlike traditional development cycles that rely on passive code reviews, VDD utilizes a specialized multi-model orchestration where a Builder AI and an Adversarial AI are placed in a high-friction feedback loop, mediated by a human developer and a granular tracking system…
What actually differentiates candidates who pass data engineering interviews vs those who get rejected?
I’m currently looking for a data engineering role and I’ve always been curious about what really separates people who make it into Google (or similar big tech) from those who don’t. Not talking about fancy schools or prestige, just real, practical differences. From your experience, what do strong candidates consistently do better, and what are the most common gaps you see? I’d really appreciate any honest, experience-based insights. Thanks!…Getting started with Claude for software development
2025 was an interesting year in many ways. One way in which it was interesting for me is that I went from an AI hater to a pretty big user. And so I’ve had a few requests for a “using Claude” guide, so I figure new year, why not give it a shot? The lack of this kind of content was something that really frustrated me starting out, so feels like a good thing to contribute to the world…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #632 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian