
Data Science Weekly - Issue 634
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #633
January 15, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
Systematically Improving Espresso: Insights from Mathematical Modeling and Experiment
Espresso, one of the most widely consumed coffee beverage formats, is also the most susceptible to variation in quality. Yet, the origin of this inconsistency has traditionally, and incorrectly, been attributed to human variations. This study’s mathematical model, paired with experiment, has elucidated that the grinder and water pressure play pivotal roles in achieving beverage reproducibility…
Tic-Tac-Toe the Hard Way
A writer and a software engineer engage in an extended conversation as they take a hands-on approach to exploring how machine learning systems get made and the human choices that shape them. Along the way they build competing tic-tac-toe agents and pit them against each other in a dramatic showdown!…Use Agents or Be Left Behind? A Personal Guide to Automating Your Own Work
I have been using agents, primarily Claude Code, for eight months to automate my own work. What you will read here is not speculation or theory. It is the product of hundreds of hours of experimentation, many failures, and some surprising successes. As a professor who does not write much code anymore, my perspective is different from the software engineering discourse that dominates Twitter…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
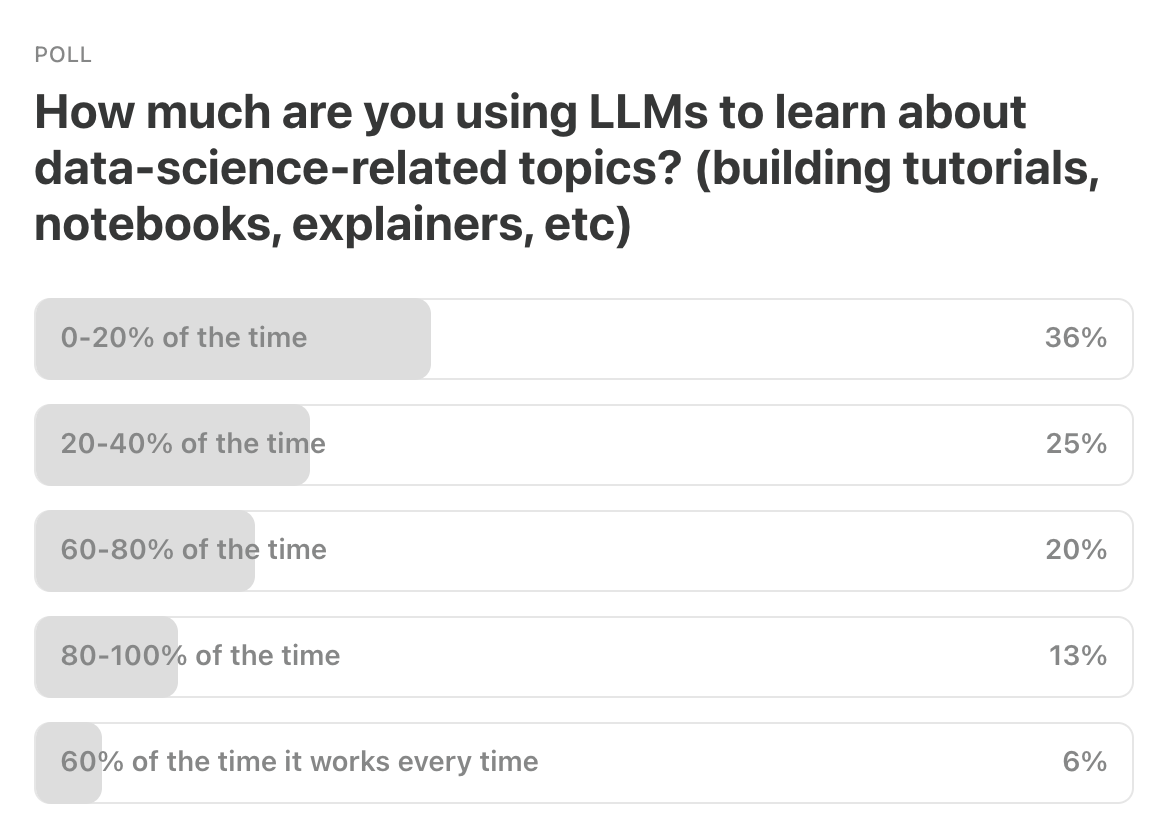
.
Data Science Articles & Videos
Using Trapezoids to Visualize Matrix Multiplication, With Applications to Data Science
I started using diagrams that have helped me internalize matrix products, and it has made the bookkeeping less cumbersome. In this article, I’ll describe the approach, which I call the trapezoid diagram. After going over some examples from linear algebra, I’ll show how it can be applied to various matrix products in data science: principal component analysis, the singular value decomposition, and fully connected layers of a neural network…Horizontalization is a natural response to increasing market size and complexity. As the market became big enough that there could be “a database company” or “an ads company,” it became advantageous for these capabilities to become their own firms rather than stay part of a single monolithic ur-company. These same firms, once independent, were able to innovate and find new markets and technologies more rapidly than they could have before, further growing the sector and continuing the process…As readers may have inferred from the title, I think the same transformation is happening in biotech and drug discovery today…
Legal Alignment for Safe and Ethical AI
Alignment of artificial intelligence (AI) encompasses the normative problem of specifying how AI systems should act and the technical problem of ensuring AI systems comply with those specifications. To date, AI alignment has generally overlooked an important source of knowledge and practice for grappling with these problems: law. In this paper, we aim to fill this gap by exploring how legal rules, principles, and methods can be leveraged to address problems of alignment and inform the design of AI systems that operate safely and ethically…Behold the power of the spectrum!
In this post, we shall explore an idea that the eigenvalues of a matrix are solutions to optimization problems. So what can one such neuron do? Turns out quite a lot! This is exactly what we shall explore in this post. Why eigenvalues? Well, because of a unique combination of three properties. They can model fairly complicated functions, we have a lot of theoretical machinery to reason about them, and we can stand on the shoulders of giants and reuse the vast talent and resources invested over decades in their reliable computation…The Question Your Observability Vendor Won’t Answer
I’m not a cynical person. I believed observability could make engineers’ lives better. But after a decade, after hundreds of conversations with teams bleeding money across every major vendor, after hearing firsthand how their vendors strong-armed them instead of helping; I’ve seen enough. The whole industry has lost the plot…Hello Data Science - A Friendly Introduction with Applications
This book is a result of our teaching of introductory data science courses at a research university, a teaching university, and a community college…The Hello Data Science book is intended for anyone who wants to take on their first data science project to look for patterns, relationships, and meaning in data - without being intimidated while still being challenged. It is currently a work in progress…Is My Pub F*cked: Find a pub that needs you
Our world-class data scientists (one guy with a spreadsheet) have developed the F*cked Pub Index™ — a groundbreaking metric that combines advanced geospatial analysis (Google Maps) with sophisticated fiscal impact modeling (basic maths) to identify the pub near you that most urgently requires your patronage…How to create a more accessible line chart
It’s a myth that accessibility means compromising on aesthetics. Instead, as writes, accessibility means prioritising communication. In this blog post, we’re going to walk through an example of creating a line chart and transforming it to make it more accessible as well as more aesthetic…Extracting Structured Data from Patient Intake Forms with DSPy and CocoIndex
Patient intake forms are indeed a rich source of structured clinical data, but traditional OCR + regex pipelines fail to reliably capture their nested, conditional, and variable structure, leaving most of that value locked in unstructured text or manual entry…In today’s example, we are going to show how to extract clean, typed, Pydantic-validated structured data directly from PDFs, using:
DSPy (for multimodal structured extraction with Gemini 2.5 Flash vision)
CocoIndex (for incremental processing, caching, and database storage)…
How to make your data analysis life easier using Positron, Raycast, and Espanso
On January 13, 2026, I was on Posit’s Data Science Lab to talk about my Positron settings and other neat workflow-y things I use to make my life easier. I’ll post the video here once it’s up. This isn’t a standard blog post—it’s mostly just a list of the stuff we talked about, with lots of different links to other resources…Alternatives to MinIO for single-node local S3
In late 2025 the company behind MinIO decided to abandon it to pursue other commercial interests. As well as upsetting a bunch of folk, it also put the cat amongst the pigeons of many software demos that relied on MinIO to emulate S3 storage locally, not to mention build pipelines that used it for validating S3 compatibility. In this blog post I’m going to look at some alternatives to MinIO. Whilst MinIO is a lot more than ‘just’ a glorified tool for emulating S3 when building demos, my focus here is going to be on what is the simplest replacement. In practice that means the following…
Contributing to base R with Coding Equity and Joy - Inside the R Contributors Project
Ella Kaye, Research Software Engineer at the University of Warwick and one of the organizers of the R Contributors project, also on Meetup, recently spoke with the R Consortium about her path into the R community and her efforts to make contributing to base R more accessible and inclusive…A Brief Introduction to the Basics of Game Theory
I provide a (very) brief introduction to game theory. I have developed these notes to provide quick access to some of the basics of game theory; mainly as an aid for students in courses in which I assumed familiarity with game theory but did not require it as a prerequisite…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #633 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian