
Data Science Weekly - Issue 635
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #635
January 22, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let's dive into some interesting links from this week.
Editor's Picks
The stable marriage problem Or, ask for things
If you happen to be a student at Berkeley, I highly recommend CS 70 (Discrete Mathematics and Probability Theory), especially when it’s taught by Anant Sahai, who’s a delightfully classic hardass immigrant professor who will probably teach you a lot about math and at least something about life. This class introduces several of my favorite pieces of math ever: RSA, Shamir’s secret sharing, error correcting codes. But the most profoundly affecting was, by far, the Stable Marriage Problem. The Secretary Problem can only dream of having this much influence on my dating life…
I Gave Claude Code 9.5 Years of Health Data to Help Manage My Thyroid Disease
I have a medical condition that’s notoriously difficult to manage: episodic Graves’ disease…I’ll be completely healthy, then suddenly lose 20+ pounds, develop tremors, battle insomnia, and watch my resting heart rate climb to uncomfortable levels…I gave Claude Code nearly a decade of Apple Watch data and asked it to find patterns with the optimal ML model. What it discovered was beyond what I expected, and it might change how I manage this condition…The irony isn’t lost on me: after trying 51 features, neural networks, LSTMs, and complex architectures, the best early detection model (an XGBoost classifier) uses three features…Data Modeling is Dead (Again), 2026 Edition. Part 1: It’s AI’s Fault!
It’s that time of the hype cycle again, where databases, data modeling, SQL, and other mainstays are written off for dead. I’ve seen this happen several times in my career, and we’re here once again…Today it’s AI, LLM, agents, etc. The argument is always that new technologies abstract away the details and “grunt work,” making data “too easy” to work with. Who cares about the database or the underlying model? They’re both obsolete, right?…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
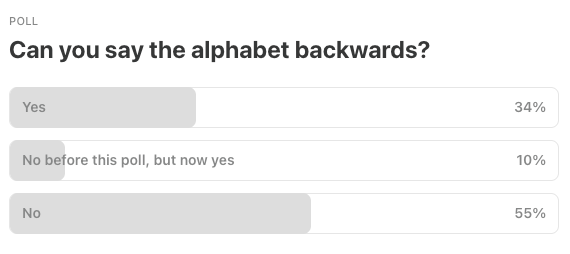
.
Data Science Articles & Videos
Unconventional PostgreSQL Optimizations
When it comes to database optimization, developers often reach for the same old tools: rewrite the query slightly differently, slap an index on a column, denormalize, analyze, vacuum, cluster, repeat. Conventional techniques are effective, but sometimes being creative can really pay off! In this article, I present unconventional optimization techniques in PostgreSQL…Safe space - what’s one task you are willing to admit AI does better than 99% of DS? [Reddit]
Let’s just admit any little function you believe AI does better, and will forever do better than 99% of Data Scientists. You know when you’re doing data cleansing, and you need a regex? Yeah The AI overlords got me beat on that…
hapnet - Population-aware haplotype network analysis and visualization in Python
hapnet is a Python package for building population-aware haplotype networks from aligned FASTA files. It integrates haplotype inference, population membership, and visualization into a reproducible, command-line workflow. hapnet constructs minimum spanning tree (MST) haplotype networks in which node size reflects haplotype frequency and shared haplotypes are represented as population-colored pie charts…plumber2 0.2.0
We’re stoked to announce the release of plumber2 0.2.0. plumber2 is a package for creating webservers in R based on either an annotation-based or programmatic workflow. It is the successor to the plumber package who has empowered the R community for 10 years and allowed them to share their R based functionalities with their organizations and the world…Spatial data science languages: commonalities and needs
Recent workshops brought together several developers, educators and users of software packages extending popular languages for spatial data handling, with a primary focus on R, Python and Julia. Common challenges discussed included handling of spatial or spatio-temporal support, geodetic coordinates, in-memory vector data formats, data cubes, inter-package dependencies, packaging upstream libraries, differences in habits or conventions between the GIS and physical modeling communities, and statistical models. The following set of recommendations have been formulated…Rolling scaled forecast accuracy
When we compute a MASE or RMSSE using a rolling origin, should the scaling factor be recalculated every time? I’ve been asked this a couple of times, so perhaps it is worth a blog post…From Human Ergonomics to Agent Ergonomics (Wes McKinney of Pandas and more fame)
I have been building a lot of new software in Go. Except that I’ve never actually written a line of Go in my life. What is going on?… Human ergonomics in programming languages matters much less now. The readability and simplicity benefits of Python help LLMs generate code, too, but viewed through the “annealing” lens of the iterative agentic loop, quicker iterations translate to net improved productivity even factoring in the “overhead” of generating code in a more verbose or more syntactically complex language…The winners of this shift to agentic engineering are the languages that have solved the build system, runtime performance, packaging, and distribution problems. Increasingly that looks like Go and Rust…rspatialdata
rspatialdata is a collection of data sources and tutorials on visualising spatial data using R…How I Structure My Data Pipelines
The medallion architecture is everywhere…The branding differs, but the core idea is the same: data flows through layers of refinement, from source to consumption…The appeal is that it gives you a simple mental model for organizing a data project. You always know roughly where to look for something. The problem is that the layer definitions are loose enough to mean different things to different people…This post shares how I’ve come to structure it. My approach combines medallion, Kimball dimensional modeling, and semantic layers into a single architecture. Each pattern solves a different problem, and when you map them onto the three layers intentionally, you get something that’s both principled and practical…
How to Switch to ty from Mypy
Python has supported type hinting for quite a few versions now, starting way back in 3.5. However, Python itself does not enforce type checking. Instead, you need to use an external tool or IDE. The first, and arguably the most popular, is mypy. Microsoft also has a Python type checker that you can use in VS Code called Pyright, and then there’s the lesser-known Pyrefly type checker and language server. The newest type checker on the block is Astral’s ty, the maker of Ruff. Ty is another super-fast Python utility written in Rust. In this article, you will learn how to switch your project to use ty locally and in GitHub Actions…Biologist talks to statistician (oldie, but goodie!)
A biologist seeks a statistician’s advice on a lab study involving apoptosis. The statistician questions the sample size and data variability, highlighting potential issues. Further discussion reveals complexities in the study’s methodology…
How the Kronecker product helped me get to benchmark performance [Reddit]
Recently had a common problem, where I had to improve the speed of my code 5x, to get to benchmark performance needed for production level code in my company…Long story short, OCR model scans a document and the goal is to identify which file from the folder with 100,000 files the scan is referring to…One way to do it is to use the “vstack” from Scipy, but this turned out to be the bottleneck when I profiled the script. Got the feedback from the main engineer that it has to be below 100ms, and I was stuck at 250ms. Long story short, there is another way of creating a “large” sparse matrix with one row repeated, and that is to use the kron method (stands for “Kronecker product”). After implementing, inference time got cut to 80ms…Making Event Study Plots Honest: A Functional Data Approach to Causal Inference
Event study plots are the centerpiece of Difference-in-Differences (DiD) analysis, but current plotting methods cannot provide honest causal inference when the parallel trends and/or no-anticipation assumption fails. We introduce a novel functional data approach to DiD that directly enables honest causal inference via event study plots. Our DiD estimator converges to a Gaussian process in the Banach space of continuous functions, enabling powerful simultaneous confidence bands…
.
Last Week's Newsletter's 3 Most Clicked Links
Use Agents or Be Left Behind? A Personal Guide to Automating Your Own Work
Systematically Improving Espresso: Insights from Mathematical Modeling and Experiment
.
* Based on unique clicks.
** Please take a look at last week's issue #634 here.
Cutting Room Floor
City Map Poster Generator: Generate beautiful, minimalist map posters for any city in the world
The Rise and Fall of the Hollywood Movie Soundtrack: A Statistical Analysis
The Mid-Skill Data Engineer is In Trouble: Your 2026 Survival Guide
Curated list of resources for those conducting research on AI policy
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian