
Data Science Weekly - Issue 636
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #636
January 29, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
Sponsor Message
See Every Journey Your Data Takes

Every week, AI makes your team faster — and your data harder to follow.
Sensitive information no longer leaves in neat files. It leaks out in fragments: a paragraph pasted into a prompt, a code snippet dropped into ChatGPT, a customer list uploaded to a “productivity” tool. Traditional DLP and DSPM see where data sits; they don’t see how knowledge actually flows.
On February 3 at 11:00 AM PT, join us as we launch Cyberhaven’s next‑generation platform for AI‑era data protection.
You’ll see how Cyberhaven acts like fleet telemetry and a black box for your data — recording every meaningful journey sensitive knowledge takes across endpoints, SaaS, cloud, and AI tools, so you can stop dangerous trips in real time.
We’ll walk through live product demos, real incidents reconstructed with data lineage, and how security teams are moving from static rules to knowledge‑flow‑aware protection.
Reserve your spot here: See how Cyberhaven traces every data journey — register
.
.
* Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
And now…let’s dive into some interesting links from this week.
Editor's Picks
The Robotics Data Pareto Frontier
The defining narrative of robotics in 2025 was not a new model architecture, but an enthusiasm for data. Despite a consensus around teleoperation as the gold standard, interest blossomed in the data and training recipes that transcend it. This appetite defined a new market category and spurred the creation of innumerable data collection startups aiming to address the heterogeneous robotics data problem…At the intersection of data companies and robotics research lies a recurring theme: human data. In just the last month, the industry’s largest players—whose initial hypotheses were staked on either hardware, teleoperation, or simulation—have all announced breakthroughs in learning from human data…
Man, these New York Times games are hard! A computational perspective
In this paper, we bring the computational lens to the study of New York Times games and consider four of them not previously studied: Letter Boxed, Pips, Strands and Tiles. We show that these games can be just as hard as they are fun. In particular, we characterize the hardness of several variants of computational problems related to these popular puzzle games…Gas Town’s Agent Patterns, Design Bottlenecks, and Vibecoding at Scale
Gas Town is a full-on stage 8 piece of tooling: using an orchestrator that manages dozens+ of other coding agents for you…On agent orchestration patterns, why design and critical thinking are the new bottlenecks, and whether we should let go of looking at code…I have grokked the basic concepts and spent more time with this manifesto than is warranted. And here is what stood out to me from the parts I could comprehend…
What’s on your mind
This Week’s Poll:
More info here:

.
Last Week’s Poll:
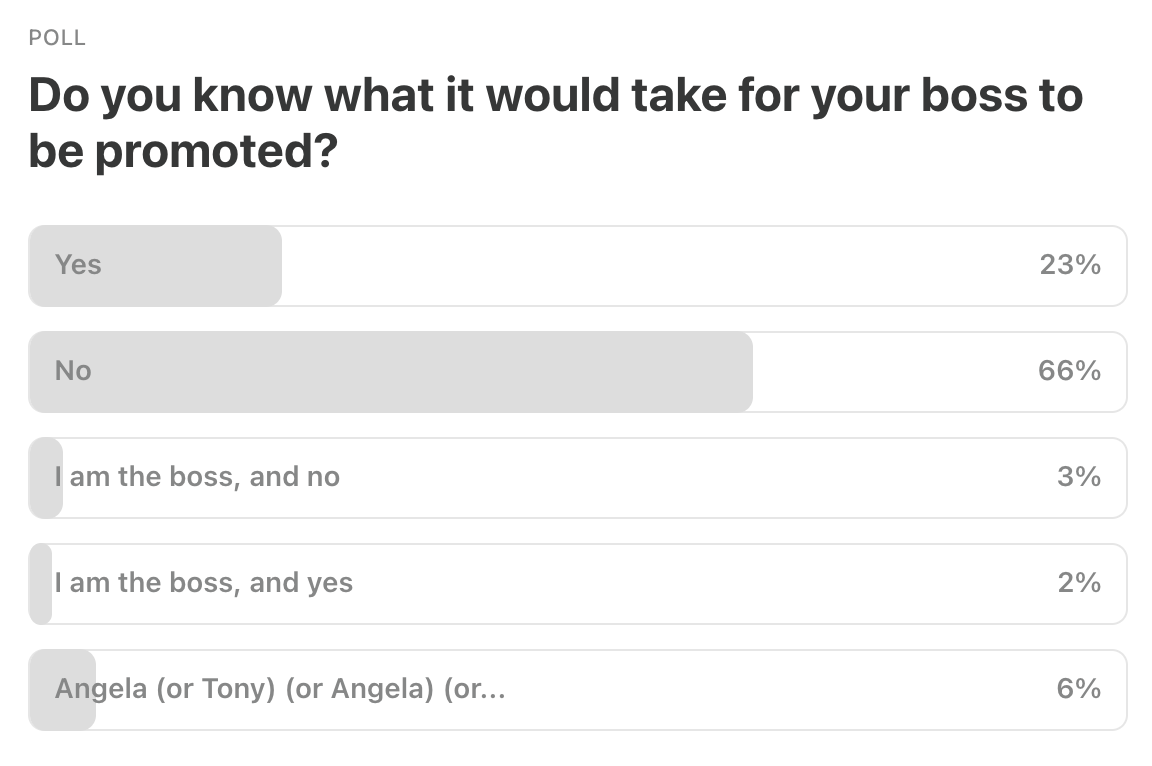
.
Data Science Articles & Videos
What Would Non-Linear Features Actually Look Like?
Debates about non-linear features have often been unconstructive for several reasons. One common issue is that people have used the word “linear feature” to mean multiple different things, leading to miscommunication. Given this, the first contribution of this post is to try to clarify this…the second contribution of this post is to identify certain constrained cases of non-linear neural networks, and then provide semi-formal arguments that in those cases, there are strong reasons to expect linear features….Do you still use notebooks in Data Science? [Reddit]
I work as a data scientist and I usually build models in a notebook and then create them into a python script for deployment. Lately, I’ve been wondering if this is the most efficient approach and I’m curious to learn about any hacks, workflows or processes you use to speed things up or stay organized…Especially now that AI tools are everywhere and GenAI still not great at working with notebooks…
Are arrays functions?
When I was a youngster first perusing the Haskell documentation for arrays, I was amused to find the following description of just what these mysterious things might be:Haskell provides indexable arrays, which may be thought of as functions whose domains are isomorphic to contiguous subsets of the integers.
I found this to be a hilariously obtuse and unnecessarily formalist description of a common data structure. Now, older, wiser, and well ensconced in the ivory towers of academia, I look at this description and think that it is actually a wonderful definition of the essence of arrays! And given that this sentence still lingers in my thoughts so many years later, who can say that it is not actually a far better piece of documentation than some more prosaic description might have been?…
Designing a Declarative Data Stack: From Theory to Practice
What started as a straightforward implementation guide for a declarative data stack quickly evolved into something more fundamental. While attempting to build a system that could define an entire data stack through a single YAML file, I encountered architectural questions that challenged my initial assumptions:Should we generate production-ready code from templates or create a boilerplate repository with best-in-class tools?
Should we leverage existing orchestration tools that already integrate with the data lifecycle or build something new?
Should we use Kubernetes/Docker as a compute engine?…
We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
Every decade brings new promises: this time, we’ll finally make building analytics platforms simple enough that we won’t need so many specialists. From SQL to OLAP to AI, the pattern repeats. Business leaders grow frustrated waiting months for a data warehouse that should take weeks, or weeks for a dashboard that should take days. Data teams feel overwhelmed by request backlogs they can never clear. Understanding why this cycle persists for fifty years reveals what both sides need to know about the nature of data analytics work…The only Muon Optimizer guide you need
Muon optimization has become one of the hottest topic in current AI landscape following its recent successes in NanoGPT speed run and more recently MuonClip usage in Kimi K2. However, on first look, it’s really hard to pinpoint the connection of orthogonalization, newton-schulz, and all its associated concepts with optimization…Before we dive deep into Muon’s architecture, it serves us well to look at one of the most fundamental algorithms, Stochastic Gradient descent as a solution to the constrained linearized improvement and understand where the solution lags behind in achieving the optimal loss minimization curve…The JAX sharding type system
Conventionally, a type system is something that classifies values into data types likefloat32orint64. However, fancy type systems go beyond data types, allowing us to talk about potentially arbitrary invariants on data; for example, if we were to talk about the “type” of a array, it would cover not only its data type, but also its shape, e.g.,f32[40, 20]. JAX’s type system of abstract values (avals) goes further than just data types and shapes and is equipped to reason about sharding related invariants. However, this type system is poorly documented, especially recent additions like reduced/unreduced axes (circa June 2025). In this blog post, I want to give a consolidated description of the sharding related aspects of JAX’s typing in explicit sharding mode, as of 2026…A 2026 look at three bio-ML opinions I had in 2024
This blog has been operating for an exceptionally long period of 1.7~ years, which means I finally have blog posts that I wrote back in 2024 to resurface, dust off, and proudly present back to you, giving you an update on how things have shifted in the 1~ years since they were written. I will do this for three articles:Piecewise Regression for Time Series Forecasting
In this tutorial, we introduce the core idea behind piecewise regression and show how it can be used to model trend change points in a time series. We begin by fitting a simple linear trend model, demonstrate why it fails in the presence of a change point, and then show how adding knot-based features enables the model to capture multiple trend regimes. For clarity and interpretability, we use linear regression in the examples, but the same approach applies to other regression models, such as Ridge, Lasso, XGBoost, or k-nearest neighbors…
How PFNs make tabular foundation models work
Before I learned about TabPFN and similar approaches, I lacked the fantasy of how one would pre-train a machine learning model on tabular data. In this post, we’ll dive into the basic thinking behind pre-training for so-called prior-data fitted networks, which underlie TabPFN and many other tabular foundation models (TFMs)…21 Lessons From 14 Years at Google
When I joined Google ~14 years ago, I thought the job was about writing great code. I was partly right. But the longer I’ve stayed, the more I’ve realized that the engineers who thrive aren’t necessarily the best programmers - they’re the ones who’ve figured out how to navigate everything around the code: the people, the politics, the alignment, the ambiguity…These lessons are what I wish I’d known earlier. Some would have saved me months of frustration. Others took years to fully understand. None of them are about specific technologies - those change too fast to matter. They’re about the patterns that keep showing up, project after project, team after team…
How do you actually track which data transformations went into your trained models? [Reddit]
I keep running into this problem and wondering if I’m just disorganized or if this is a real gap - The scenario:Train a model in January, get 94% accuracy
Write paper, submit to conference
Reviewer in March asks: “Can you reproduce this with different random seeds?”
I go back to my code and... which dataset version did I use? Which preprocessing script? Did I merge the demographic data before or after normalization?…
How to Build a Recommendation System at Scale: Insights from Instacart
A Senior ML Engineer’s perspective on production constraints, rules vs ML and the workflow behind large-scale recommender systems…
.
Last Week's Newsletter's 3 Most Clicked Links
I Gave Claude Code 9.5 Years of Health Data to Help Manage My Thyroid Disease
Data Modeling is Dead (Again), 2026 Edition. Part 1: It’s AI’s Fault!
.
* Based on unique clicks.
** Please take a look at last week's issue #635 here.
Cutting Room Floor
Beautiful Mermaid Diagrams: Mermaid Rendering, made beautiful
Debugging your R code with the browser() function and a second pipe operator
futurize: Parallelize Common R Functions via a “Magic” Touch
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian