
Data Science Weekly - Issue 637
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #637
February 05, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let’s dive into some interesting links from this week.
Editor's Picks
Points, Rules, Weights, Distributions: The Elements of Machine Learning
In this post, I explore how to deconstruct machine learning…which elements remain if we put random forests, CNNs, and k-nearest neighbors into a pressure cooker? What’s left are four learnable elements that make up most of modern machine learning. You can think of them as ways of storing and applying patterns to (intermediate) features…
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models…to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer…data poems
Short stories I tried to tell with numbers…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
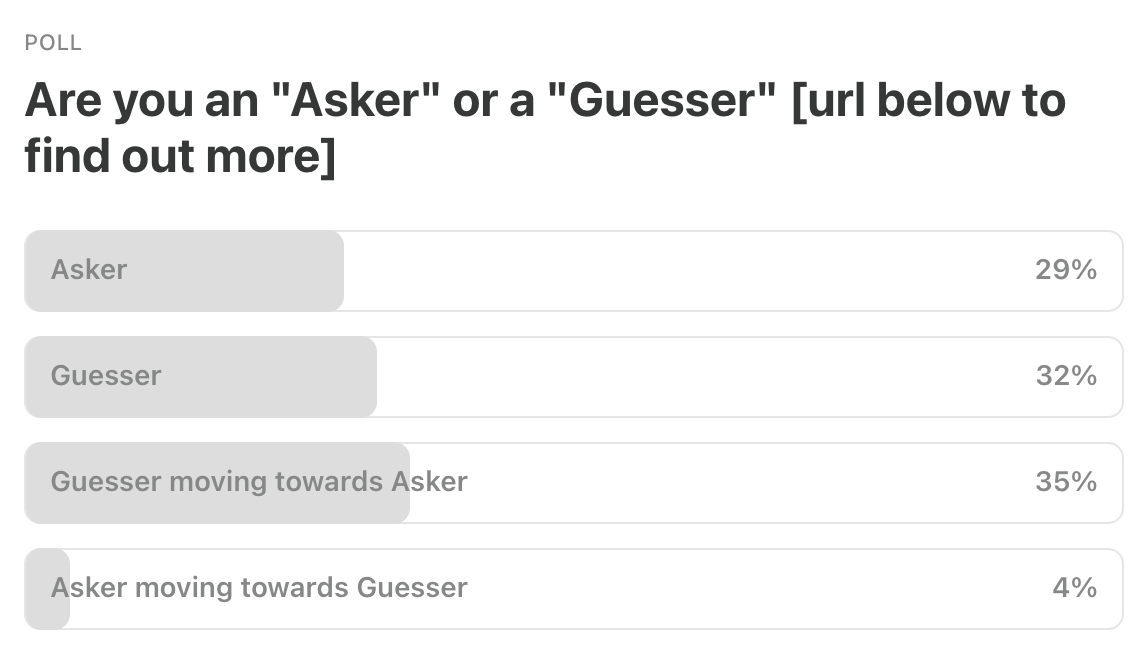
.
Data Science Articles & Videos
Maybe You’re Wrong - Quantiles, Prediction Intervals, and what theory can tell you about the future
This is a live blog of Lecture 16 of the 2025 edition of my graduate machine learning class “Patterns, Predictions, and Actions.”…I’ve been reading Frank Harrell’s critiques of backward elimination, and his arguments make a lot of sense to me. That said, if the method is really that problematic, why does it still seem to work reasonably well in practice? My team uses backward elimination regularly for variable selection, and when I pushed back on it, the main justification I got was basically “we only want statistically significant variables.” Am I missing something here? When, if ever, is backward elimination actually defensible?…
Building a Global, Event-Driven Platform: Our Ongoing Journey, Part 1
A few years ago, our platform reached a point where the way we’d always built software simply wasn’t enough anymore. The monolith that powered our early success had served us well, but as the business expanded across the continent, it started showing real limits. Global growth forced us to confront problems we couldn’t ignore: latency across regions, unpredictable load patterns, and an architecture that didn’t match the scale of the company. We needed to rethink how the entire system worked, from the shape of our data to the boundaries between teams…The Q, K, V Matrices
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input. In this write-up, we will go through the construction of these matrices from the ground up…Eight Lessons Learned in Two Years of Ph.D.
If you are starting your Ph.D. soon, you might be wondering about how you should go about it, how to think about your research, which habits to adopt, and which ones to abandon. That was me when I started my program two years ago. Then I started a habit that proved to be quite beneficial: I dedicated a page in my research notebook titled Lessons Learned. I made sure to update this page on a semi-regular basis, typically whenever I learn something from my mentors/advisors, reflect on my progress, or come across an “Aha” moment about something that I should have done differently. This blog post serves to elaborate and expand on some of the key entries on that notebook page…Build chatbot to talk with your PostgreSQL database using Python and local LLM
In this article, we will show you how to build a chatbot application that can query a PostgreSQL database and present the results as tables and charts. We will use a local, open-source LLM model, GPT-OSS 20B, served with Ollama. The chatbot application is built in Python with open-source libraries and can be extended and customized in many ways (the sky is the limit). The whole solution works completely offline. Everything runs locally: a local database, a local LLM, and your application. No internet connection is required…A Theorist’s Guide to Empirical Research
I started my career as a computer science theorist, even going so far as proving a couple of theorems in combinatorics. Over time, my interests drifted towards the more empirical, and I now pride myself as an empirical LLM privacy and security researcher. A result of this is that I often get asked by junior researchers about the process – what is empirical research like from the point of view of a theorist, and how do you succeed at it? This post is a short version of the advice I give them…Why Do Monads Matter?
My goal is to demonstrate for you, with details and examples:Where category-based intuition and ideas, and monads in particular, come from in computer programming.
Why the future of programming does lie in these ideas, and their omission in today’s mainstream languages has cost us dearly.
What the state of the art looks like in applying category-based ideas to problems in computer programming….
Algorithms for Private Data Analysis
This course is on algorithms for differentially private analysis of data. As necessitated by the nature of differential privacy, this course will be theoretically and mathematically based. References to practice will be provided as relevant, especially towards the end of the course…
All Your Data R Fixed: Transforming Your RHS Covariates Won’t Fix Your Outcome Distribution
In all conventional regression models, the data are fixed–they don’t have a probability distribution. This means transforming your data with logs or other functions won’t change the probability distribution of your outcome…What’s the difference between statistical significance and substantial significance?
All that statistical significance really tells you is how confident you are that a measured effect is not zero. Or, more formally, using our null world idea, if something is significant, it means that in a hypothetical world where the effect is actually zero, the probability of seeing your measured effect is really low (less than 5%). But most of the time we don’t care if an effect is maybe zero or not zero. We want to know if the effect actually matters!…
From Individual Contributor to Team Lead — what actually changes in how you create value? [Reddit]
I recently got promoted from individual contributor to data science team lead, and honestly I’m still trying to recalibrate how I should work and think…As an IC, value creation was pretty straightforward: pick a problem, solve it well, ship something useful. If I did my part right, the value was there. Now as a team lead, the bottleneck feels very different…Would love to hear how people here think about this shift. I suspect this is one of those transitions that looks simple from the outside but is actually pretty deep…Sarah Johnson’s CLAUDE.md for Modern R Development
This document captures current best practices for R development, emphasizing modern tidyverse patterns, performance, and style…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #636 here.
Cutting Room Floor
.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything you need to know about getting a data science job, based on answers to thousands of reader emails like yours. The course has three sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,750 subscribers by sponsoring this newsletter. 30-35% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian