
Data Science Weekly - Issue 657
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #657
June 25, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let’s dive into some interesting links from this week.
Editor's Picks
United Kingdom prime ministers
UK has had a spurt of prime ministerial turnover in the past decade or so, but it’s by no means unprecedented. I download data from Wikipedia and try several ways to visualise that turnover…
How The Heck Do Synthesizers Work? (An Interactive Exploration)
Synthesizers have remained a staple of modern music. From iconic video game soundtracks to Hans Zimmer’s scores, from Radiohead to the Stranger Things theme. We hear more synthesized music than we even realize. So how do they actually work?…Surprising lessons from my research scientist job search
There are two recent blog posts from Alisa and Silvia, both CS PhD students, on how they prepared and got into frontier labs such as OpenAI and Google Deepmind. I highly recommend them, and after seeing the reactions on Twitter, I want to share a different angle: what surprised me during my own research scientist job search…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
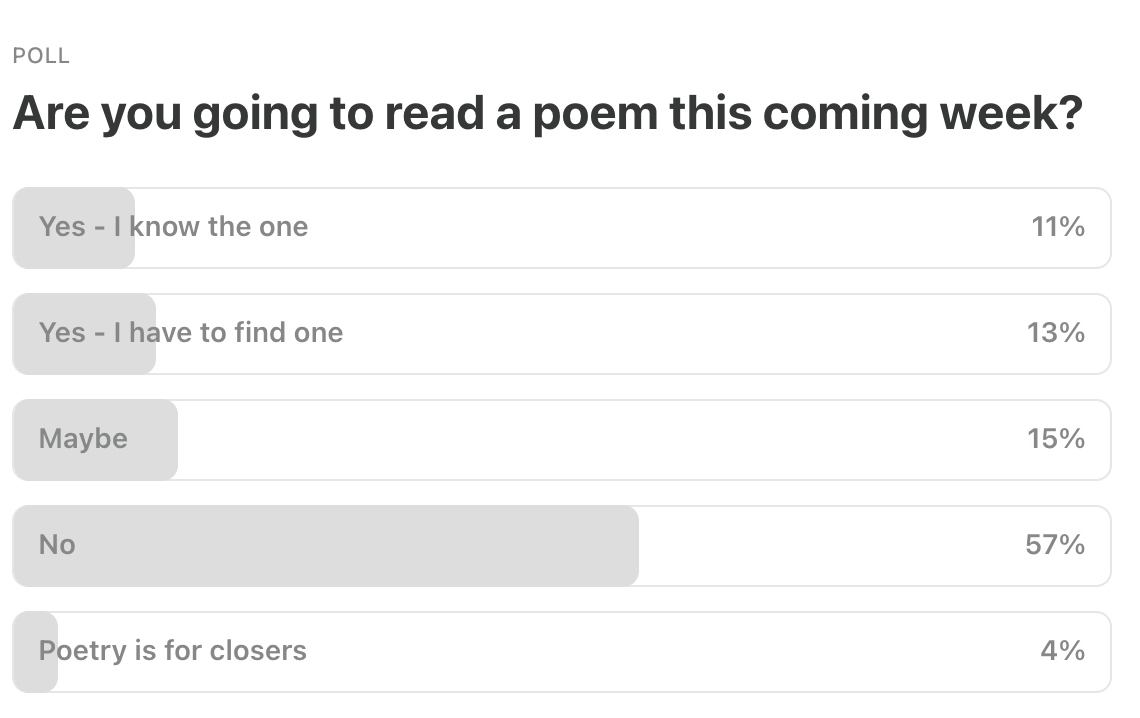
.
Data Science Articles & Videos
The PCA Mistake I Made During My PhD (and How to Avoid It in R)
A few years into my PhD, I ran a principal component analysis on a dataset I’d spent six months collecting, looked at the scree plot, picked “the number of components that looked right,” and moved on. A reviewer later asked me to justify that number. I couldn’t. Not with anything more rigorous than “the elbow looked like it was there.”…It turns out Analytics was a great career to go into even in a world with AI [Reddit]
Maybe two or three years ago I lamented the fact I had never gone into software development in spite of the fact I probably had the coding mindset for it, regretting the tedious and stressful aspects of Analytics as well as lower overall pay. Now with AI leading to massive layoffs and / or reduce hiring in software development and other Engineering fields, I’m thinking Analytics was a good field to specialize in since it has that sweet spot of being just close enough to the business and just close enough to the tech side that it is hard to automate away via AI. Furthermore, I think demand for analysts in general to understand data and accommodate reporting changes will also increase if AI is accelerating software changes and changes to data models and systems…
minFLUX - A hackable implementation of FLUX diffusion models
A simplified educational PyTorch implementation of FLUX.1 and FLUX.2 diffusion transformers (DiT) by Black Forest Labs. Built for understanding rectified flow matching, joint attention, and the key design choices behind FLUX with verifiable line-by-line source mappings to the official codebases…Data-driven discovery of dynamical models in biology
In this review, we survey approaches for model discovery in biological dynamical systems, focusing on three methodological families: regression-based methods, network-based architectures, and decomposition techniques. We compare their ability to address three core goals: forecasting future states, identifying interactions, and characterizing system states. Representative methods are applied to a common benchmark, the Oregonator model, a minimal nonlinear oscillator that captures shared design principles of chemical and biological systems. By highlighting strengths, limitations, and interpretability, we aim to guide researchers in selecting tools for analyzing complex, nonlinear, and high-dimensional dynamics in the life sciences…Scaling laws are one of the most critical empirical findings in deep learning. The observation is simple in form: the training loss L decreases predictably as we scale up model size N, dataset size D, and compute C, following a power-law curve, which appears as a straight line on a log-log plot. We can view scaling laws as a framework for describing the relationship between compute, loss, model size and data; at its core, it is about how to allocate precious compute optimally between N and D. This predictability makes scaling laws highly valuable in practice. A common workflow is to fit scaling laws on a handful of small runs and then extrapolate to estimate the token and compute requirements for larger models….
ML Foundations (prerequisites) for Post-Training | RLHF Book Course, Lecture 0
In this video I try to cover a bunch of math, LLM training fundamentals, and probability concepts that come up again and again in post-training content (and this book). We cover things like the role of mid-training, definitions of KL, entropy & cross-entropy, getting LM probabilities from a sequence, etc…tsauditor - data quality auditing library for time-series tabular data in financial and sensor domains
A data-quality auditing library for time-series tabular data, with a focus on financial and sensor domains. tsauditor scans a DataFrame and returns a structured report of structural problems, anomalies, and — its core contribution — data-leakage between features and the prediction target…General-purpose large language models outperform specialized clinical AI tools on medical benchmarks
Specialized clinical artificial intelligence (AI) tools are entering medical practice at scale1,2. These proprietary large language model (LLM)-based tools promise superior clinical performance to general-purpose frontier LLMs as a result of domain-specific training or retrieval-augmented generation (RAG)3. Yet, their architectures, base models and training pipelines are not public…This study is an independent, quantitative comparison of clinical AI tools against frontier LLMs using real-world physician queries from the course of care. Clinical AI tools lagged behind frontier models on every evaluation: knowledge, expert alignment and real-world clinical use across multiple dimensions…Moneyball for Physical AI - A Scaling Law Perspective for Marginal Utility per Dollar
This essay builds a framework for the marginal utility of data, and uses it to discuss value accrual in Physical AI. We take the perspective of the scaling laws that guide how loss behaves with data, and the unit economics that govern what a dollar of data is worth. Together they give an approximate marginal utility per dollar, the on-base percentage of physical AI…
Five Eras in the Evolution of Probability and Statistics
Statistics isn’t a new thing. It dates back at least fifty centuries beginning as counts in the form of tally marks for keeping track of crops, animals, people, and time. From there, it evolved with the demands of government and business, supported by academic inquiry and the growth of technology…Interested in learning more about digital archives?
Interested in learning more about digital archives? Here are some resources to get you started! Most are targeted at a general audience, but some of them are more technical. I’ve included descriptions to help you navigate. Let me know if you have any topics you’d like me to cover here!..
Anyone actually believe dashboards are going away? [Reddit]
keep seeing this take that ai agents are going to replace dashboards entirely. like why even look at a chart when the ai can just tell you "stop spending on this channel" or whatever. and i get the appeal of that but i think it misses something pretty fundamental about how people actually make decisions…Data for fitting models versus data for predicting from models
Answering a question that came up from a student recently. Say you have 20 surveys of reef fish biomass at different locations. Then you also have gridded data with environmental covariates. The gridded data is for all reefs everywhere. The goal is to predict fish biomass at all reefs everywhere. Here’s an older post that walks through the steps in R with older packages (you will want to update raster to terra, everything else should work). The statistically correct workflow would look like this...
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Please take a look at last week's issue #656 here.
Cutting Room Floor
.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
This is a strong mix because it keeps data science from becoming too inward-looking. A politics visualization, an interactive synthesizer explainer, research-scientist job-search notes, and the usual ML links all train the same muscle: turning messy systems into something intelligible.