
Data Science Weekly - Issue 658
Curated news, articles and jobs related to Data Science, AI, & Machine Learning

Issue #659
June 26, 2026
Hello!
Once a week, we write this email to share the links we thought were worth sharing in the Data Science, ML, AI, Data Visualization, and ML/Data Engineering worlds.
And now…let’s dive into some interesting links from this week.
Editor's Picks
Where to Find the Colors Your Screen Can’t Show You
There are colors that I want to show you, but I can’t. They exist in the real world. You probably saw some of them today, but I can’t show them to you on a screen. A digital photograph can’t capture them, and your screen can’t display them. No game you’ve ever played has contained them. Unless you have specialized equipment, they are entirely absent from the digital world…
Finding the Best Dog Treat with Statistics: A Greyhound, five treats, and a Bradley-Terry model
Bebop, my 83lb, 33 inch tall, Greyhound, loves three things: running fast, following me around the house, and treats. Whether it’s a chew treat, pizza out of a child’s hand who strayed too far from a party, or a small tray of cat food, he has a nose for what he likes and the athleticism to give him a fair shot at getting it. I’ve watched him eat for years, so it was upsetting to realize I don’t know what his favorite snack is, and can’t easily ask him. Fortunately for Bebop’s palate, the Bradley-Terry model gives us a way to figure out a “strength” of treat from pairwise comparisons…Generative Artificial Intelligence creates delicious, sustainable, and nutritious burgers
Using burgers as a model system, the generative AI rediscovers the classic Big Mac without explicit supervision and generates novel burgers optimized for deliciousness, sustainability, or nutrition. Compared to the Big Mac, its delicious burgers score the same or better in overall liking, flavor, and texture in a blinded sensory evaluation conducted in a restaurant setting with 101 participants; its mushroom burger achieves an environmental impact score more than an order of magnitude lower; and its bean burger attains nearly twice the nutritional score. Together, these results establish generative AI as a quantitative framework for learning human taste and navigating complex trade-offs in principled food design…
What’s on your mind
This Week’s Poll:
.
Last Week’s Poll:
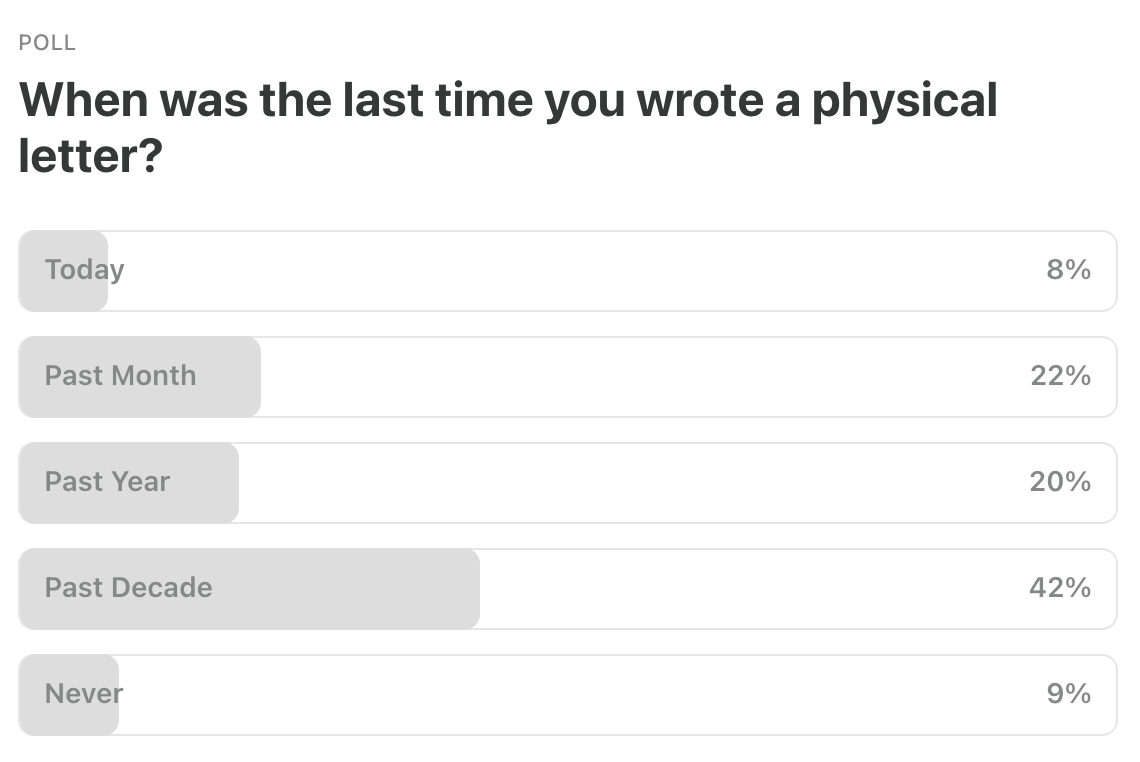
.
Data Science Articles & Videos
HackerRank open sourced its ATS. My resume scored 90/100. Oh wait 74/100. No — 88/100. Actually 83/100
How hiring is becoming a luck filter…Here a quick rundown on how the tool works: Your PDF gets parsed into text. An LLM is called six times to extract structured information — your basics, work history, education, skills, projects, awards. It pulls your GitHub profile, scans your top repos, appends them as extra context. Then everything gets fed into the LLM at once to be graded…What is the most underrated skill every data scientist should develop? [Reddit]
Beyond Python, machine learning, and statistics, which skill has made the biggest difference in solving real-world data science problems and delivering business value?…
Can AI Become a Real Data Scientist? | Gaël Varoquaux on scikit-learn, Probabl & Scientific Judgment
In this episode of Creative Difference, Maxime Gabella speaks with Gaël Varoquaux, co-founder of scikit-learn and Probabl, about the future of AI, statistical learning, and scientific judgment. They discuss the difference between generative AI and statistical machine learning, why current AI agents can write code but still struggle with rigorous data analysis, and why tools like scikit-learn and Skore may become essential for trustworthy AI systems. The conversation explores memorization, generalization, uncertainty, data leakage, evaluation, human-in-the-loop science, and the role of a “statistical harness” for AI agents. It also moves into deeper questions: why real-world science is harder than mathematics, why data collection and intervention still matter, how categories shape reality, and what creativity means for humans and machines…Vibe Coding vs. Vibe Engineering: How Systems Scale Without Collapsing
What is the difference between vibe coding and vibe engineering? Learn how modern software teams evolve from rapid experimentation to enterprise-grade systems without drowning in technical debt or sliding into technical bankruptcy…Why Adjusted Regression Coefficients Are Less Descriptive Than They Look
It is common for researchers to investigate “factors associated with” an outcome by collecting many candidate variables, entering them together into one multivariable regression, and reporting the ones whose mutually-adjusted coefficients reach significance (Lewer et al., 2025). In this interactive article I explain why that practice misleads — not because of the usual problems of causal inference or multiple comparison, but even in descriptive studies, where researchers are genuinely interested in associations…
From Julia to Rust: a differentiable tensor stack for scientific computing in the agentic AI era
The Rust ecosystem has changed a lot in the last few years. crates.io went from 602 crates in 2015 to roughly 210,000 in 2026 (data). For dense linear algebra there is faer; for GPU kernels, CubeCL; for generic numerics,num-traitsandnum-complex. There are also libraries at nearby layers: ndarray for arrays, nalgebra and faer for linear algebra, Burn and candle for deep learning, and numr for a NumPy-style array API. What we needed was the layer between them: a scientific-computing tensor stack with column-major storage, dynamic shapes, eager and traced autodiff, einsum, FFT, CPU/CUDA backends, and extensible operations. That is what tenferro-rs is for…This post explains why we are building it, and why we chose Rust now that code is no longer written only by humans…Gribouille - Create elegant graphics with the Grammar of Graphics for Typst.
Compose charts by layering data, aesthetic mappings, geoms, scales, and themes. The same grammar as ggplot2 and plotnine, drawn natively in Typst…Open-source geo-experiment tools are not interchangeable
We ran 32,000 simulated experiments across four common marketing scenarios to benchmark four leading open-source geo-experiment tools. Because we use synthetic data where the true campaign effect is known in advance, we can measure how well each tool recovers it. These four tools are often treated as interchangeable, and they are not. Where they diverge — sharply, at times — is in how they handle uncertainty: how often their confidence intervals contain the true incremental effect, how often they declare winning results that aren’t real (false positives), and how often they come back inconclusive when a real incremental effect exists (false negatives)…Ten years of ClickHouse in open source
ClickHouse was released in open source on Jun 15 2016, ten years ago. Since then, it became the most popular open source analytical database with more than 2000 contributors…
What happens when you run a CUDA kernel
Here’s a simple CUDA program. It adds two vectors…Compiled for an RTX 4090, and launched, it does correctly work out that 1 + 1 = 2, a million times…Telling you that involved tens of millions of CPU instructions, a couple of device files, nine hundred ioctls, and one memory-mapped doorbell register. In this post, we’ll follow this one kernel from the code down to the warps, and back up to the answer…Map Clustering is Not My Favorite
Friends, this post has been in the making for maybe, 20 years. Google Maps (and me) are (at least) that old. And mapping, of course, existed before that; those were the days. But ~~~20 years ago, or like a year after that, something appeared on our collective mapping radars that I have not been able to shake off since - and which I haven’t kvetched about in writing, ever, for everyone to “enjoy”. Enjoy! It’s a Greg Rant! Amazing… What happened ~~~~20 years ago, after Google Maps was hoisted on us all, was that “people wanted to see more than 1 point on a map” and sometimes that meant 100 points, or a thousand! And things were not easy or good then. I mean, 1000 points, that’s a LOT. But then, who said 1000 points (was it you?) was too much to show? Well… browsers…
Data Directors - what’s your next step? [Reddit]
For anyone who has had a director of data or data director title in the past - where are you now? Similar role at a different company? Same role? Eventually C-suite? What’s the plan?…Zen and the Art of AI Research (temperament >> talent)
So you want to do AI research? It’s true that no one really teaches you how. Not directly, anyway. The way to get started is pretty simple: some combination of (i) reading and (ii) building stuff. You can’t do one without the other. You become a researcher through the combination. It turns out the process of becoming a great researcher is not unlike learning to meditate…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** You can find last week's issue #657 here.
Cutting Room Floor
Generative AI for material design: A mechanics perspective from burgers to matter
Faster KNN search in Manticore: 2-pass HNSW, batched distances, and AVX-512
Hnswlib - Header-only C++/python library for fast approximate nearest neighbors
Matrix Orthogonalization Improves Memory in Recurrent Models
Small Molecules Have More Information Per Atom Than Biologics
.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian